 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Modeling of Metric-Based Serverless Computing Platforms
Feb 23, 2022



Analytical performance models are very effective in ensuring the quality of service and cost of service deployment remain desirable under different conditions and workloads. While various analytical performance models have been proposed for previous paradigms in cloud computing, serverless computing lacks such models that can provide developers with performance guarantees. Besides, most serverless computing platforms still require developers' input to specify the configuration for their deployment that could affect both the performance and cost of their deployment, without providing them with any direct and immediate feedback. In previous studies, we built such performance models for steady-state and transient analysis of scale-per-request serverless computing platforms (e.g., AWS Lambda, Azure Functions, Google Cloud Functions) that could give developers immediate feedback about the quality of service and cost of their deployments. In this work, we aim to develop analytical performance models for the latest trend in serverless computing platforms that use concurrency value and the rate of requests per second for autoscaling decisions. Examples of such serverless computing platforms are Knative and Google Cloud Run (a managed Knative service by Google). The proposed performance model can help developers and providers predict the performance and cost of deployments with different configurations which could help them tune the configuration toward the best outcome. We validate the applicability and accuracy of the proposed performance model by extensive real-world experimentation on Knative and show that our performance model is able to accurately predict the steady-state characteristics of a given workload with minimal amount of data collection.
MLProxy: SLA-Aware Reverse Proxy for Machine Learning Inference Serving on Serverless Computing Platforms
Feb 23, 2022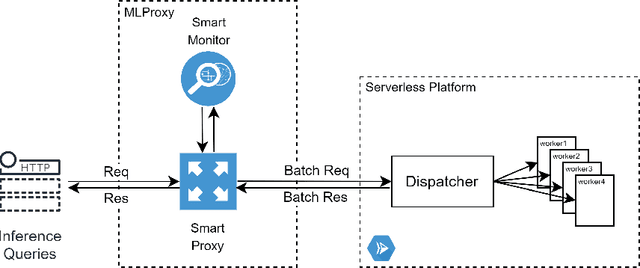
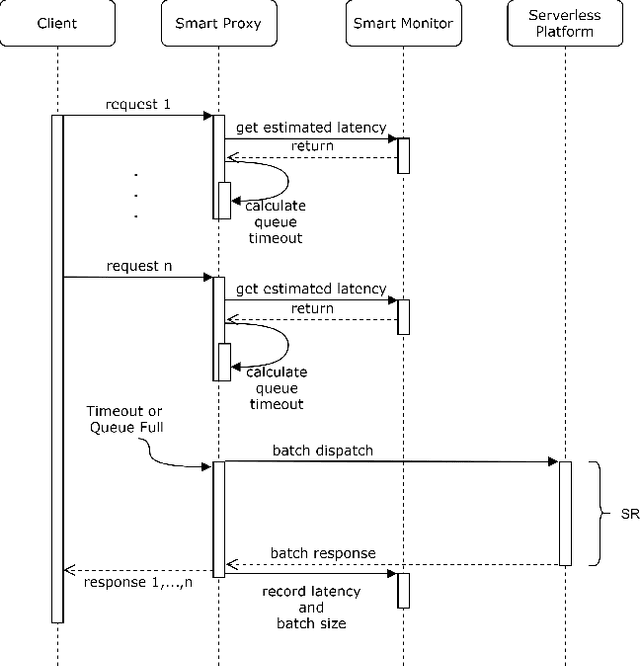

Serving machine learning inference workloads on the cloud is still a challenging task on the production level. Optimal configuration of the inference workload to meet SLA requirements while optimizing the infrastructure costs is highly complicated due to the complex interaction between batch configuration, resource configurations, and variable arrival process. Serverless computing has emerged in recent years to automate most infrastructure management tasks. Workload batching has revealed the potential to improve the response time and cost-effectiveness of machine learning serving workloads. However, it has not yet been supported out of the box by serverless computing platforms. Our experiments have shown that for various machine learning workloads, batching can hugely improve the system's efficiency by reducing the processing overhead per request. In this work, we present MLProxy, an adaptive reverse proxy to support efficient machine learning serving workloads on serverless computing systems. MLProxy supports adaptive batching to ensure SLA compliance while optimizing serverless costs. We performed rigorous experiments on Knative to demonstrate the effectiveness of MLProxy. We showed that MLProxy could reduce the cost of serverless deployment by up to 92% while reducing SLA violations by up to 99% that can be generalized across state-of-the-art model serving frameworks.