 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Classification in Indoor Environments for Robots using Context Based Word Embeddings
Paper and Code
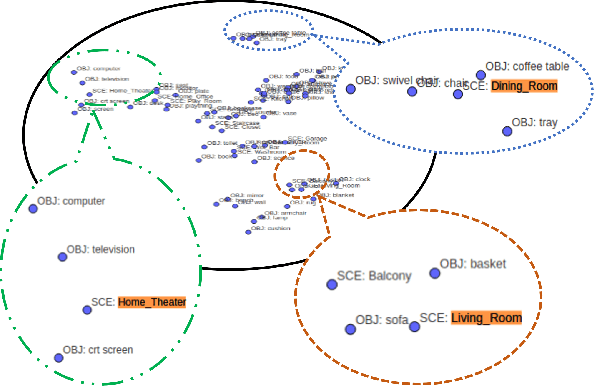

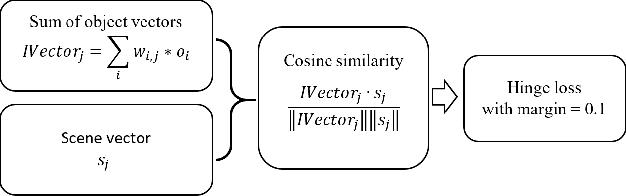

Scene Classification has been addressed with numerous techniques in computer vision literature. However, with the increasing number of scene classes in datasets in the field, it has become difficult to achieve high accuracy in the context of robotics. In this paper, we implement an approach which combines traditional deep learning techniques with natural language processing methods to generate a word embedding based Scene Classification algorithm. We use the key idea that context (objects in the scene) of an image should be representative of the scene label meaning a group of objects could assist to predict the scene class. Objects present in the scene are represented by vectors and the images are re-classified based on the objects present in the scene to refine the initial classification by a Convolutional Neural Network (CNN). In our approach we address indoor Scene Classification task using a model trained with a reduced pre-processed version of the Places365 dataset and an empirical analysis is done on a real-world dataset that we built by capturing image sequences using a GoPro camera. We also report results obtained on a subset of the Places365 dataset using our approach and additionally show a deployment of our approach on a robot operating in a real-world environment.