 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Prompt Learning with SAM for Few-shot Scanning Probe Microscope Image Segmentation
Oct 16, 2024



The Segment Anything Model (SAM) has demonstrated strong performance in image segmentation of natural scene images. However, its effectiveness diminishes markedly when applied to specific scientific domains, such as Scanning Probe Microscope (SPM) images. This decline in accuracy can be attributed to the distinct data distribution and limited availability of the data inherent in the scientific images. On the other hand, the acquisition of adequate SPM datasets is both time-intensive and laborious as well as skill-dependent. To address these challenges, we propose an Adaptive Prompt Learning with SAM (APL-SAM) framework tailored for few-shot SPM image segmentation. Our approach incorporates two key innovations to enhance SAM: 1) An Adaptive Prompt Learning module leverages few-shot embeddings derived from limited support set to learn adaptively central representatives, serving as visual prompts. This innovation eliminates the need for time-consuming online user interactions for providing prompts, such as exhaustively marking points and bounding boxes slice by slice; 2) A multi-source, multi-level mask decoder specifically designed for few-shot SPM image segmentation is introduced, which can effectively capture the correspondence between the support and query images. To facilitate comprehensive training and evaluation, we introduce a new dataset, SPM-Seg, curated for SPM image segmentation. Extensive experiments on this dataset reveal that the proposed APL-SAM framework significantly outperforms the original SAM, achieving over a 30% improvement in terms of Dice Similarity Coefficient with only one-shot guidance. Moreover, APL-SAM surpasses state-of-the-art few-shot segmentation methods and even fully supervised approaches in performance. Code and dataset used in this study will be made available upon acceptance.
MECPformer: Multi-estimations Complementary Patch with CNN-Transformers for Weakly Supervised Semantic Segmentation
Mar 19, 2023The initial seed based on the convolutional neural network (CNN) for weakly supervised semantic segmentation always highlights the most discriminative regions but fails to identify the global target information. Methods based on transformers have been proposed successively benefiting from the advantage of capturing long-range feature representations. However, we observe a flaw regardless of the gifts based on the transformer. Given a class, the initial seeds generated based on the transformer may invade regions belonging to other classes. Inspired by the mentioned issues, we devise a simple yet effective method with Multi-estimations Complementary Patch (MECP) strategy and Adaptive Conflict Module (ACM), dubbed MECPformer. Given an image, we manipulate it with the MECP strategy at different epochs, and the network mines and deeply fuses the semantic information at different levels. In addition, ACM adaptively removes conflicting pixels and exploits the network self-training capability to mine potential target information. Without bells and whistles, our MECPformer has reached new state-of-the-art 72.0% mIoU on the PASCAL VOC 2012 and 42.4% on MS COCO 2014 dataset. The code is available at https://github.com/ChunmengLiu1/MECPformer.
WegFormer: Transformers for Weakly Supervised Semantic Segmentation
Mar 16, 2022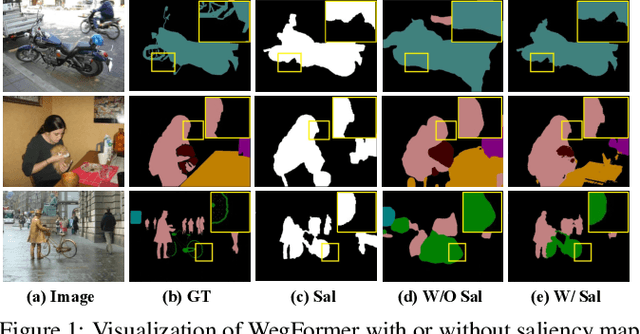
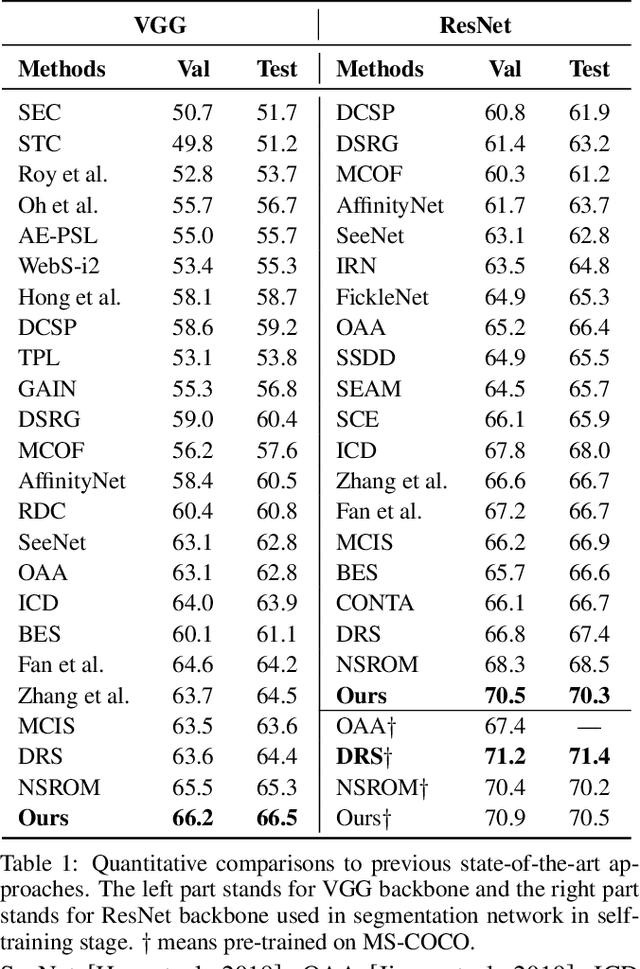


Although convolutional neural networks (CNNs) have achieved remarkable progress in weakly supervised semantic segmentation (WSSS), the effective receptive field of CNN is insufficient to capture global context information, leading to sub-optimal results. Inspired by the great success of Transformers in fundamental vision areas, this work for the first time introduces Transformer to build a simple and effective WSSS framework, termed WegFormer. Unlike existing CNN-based methods, WegFormer uses Vision Transformer (ViT) as a classifier to produce high-quality pseudo segmentation masks. To this end, we introduce three tailored components in our Transformer-based framework, which are (1) a Deep Taylor Decomposition (DTD) to generate attention maps, (2) a soft erasing module to smooth the attention maps, and (3) an efficient potential object mining (EPOM) to filter noisy activation in the background. Without any bells and whistles, WegFormer achieves state-of-the-art 70.5% mIoU on the PASCAL VOC dataset, significantly outperforming the previous best method. We hope WegFormer provides a new perspective to tap the potential of Transformer in weakly supervised semantic segmentation. Code will be released.