Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DKU-DukeECE Diarization System for the VoxCeleb Speaker Recognition Challenge 2022
Paper and Code
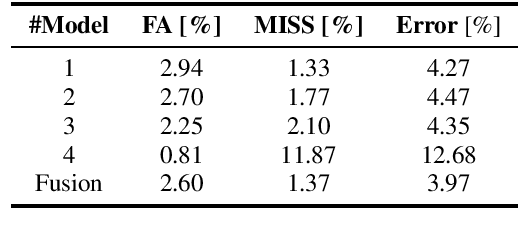

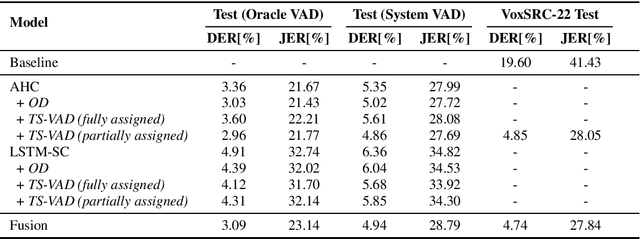
This paper discribes the DKU-DukeECE submission to the 4th track of the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22). Our system contains a fused voice activity detection model, a clustering-based diarization model, and a target-speaker voice activity detection-based overlap detection model. Overall, the submitted system is similar to our previous year's system in VoxSRC-21. The difference is that we use a much better speaker embedding and a fused voice activity detection, which significantly improves the performance. Finally, we fuse 4 different systems using DOVER-lap and achieve 4.75 of the diarization error rate, which ranks the 1st place in track 4.
* arXiv admin note: substantial text overlap with arXiv:2109.02002
View paper on