 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaugh Betrays You? Learning Robust Speaker Representation From Speech Containing Non-Verbal Fragments
Nov 07, 2022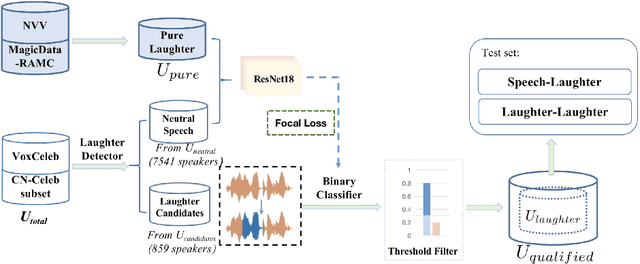

The success of automatic speaker verification shows that discriminative speaker representations can be extracted from neutral speech. However, as a kind of non-verbal voice, laughter should also carry speaker information intuitively. Thus, this paper focuses on exploring speaker verification about utterances containing non-verbal laughter segments. We collect a set of clips with laughter components by conducting a laughter detection script on VoxCeleb and part of the CN-Celeb dataset. To further filter untrusted clips, probability scores are calculated by our binary laughter detection classifier, which is pre-trained by pure laughter and neutral speech. After that, based on the clips whose scores are over the threshold, we construct trials under two different evaluation scenarios: Laughter-Laughter (LL) and Speech-Laughter (SL). Then a novel method called Laughter-Splicing based Network (LSN) is proposed, which can significantly boost performance in both scenarios and maintain the performance on the neutral speech, such as the VoxCeleb1 test set. Specifically, our system achieves relative 20% and 22% improvement on Laughter-Laughter and Speech-Laughter trials, respectively. The meta-data and sample clips have been released at https://github.com/nevermoreLin/Laugh_LSN.
Building Bilingual and Code-Switched Voice Conversion with Limited Training Data Using Embedding Consistency Loss
Apr 22, 2021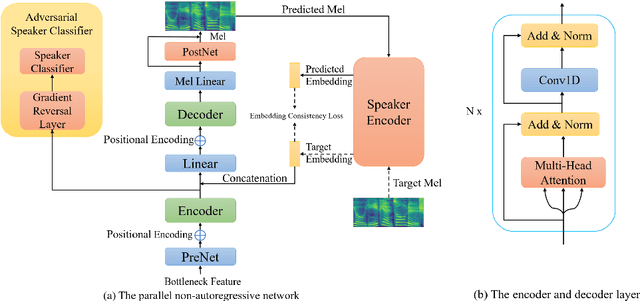

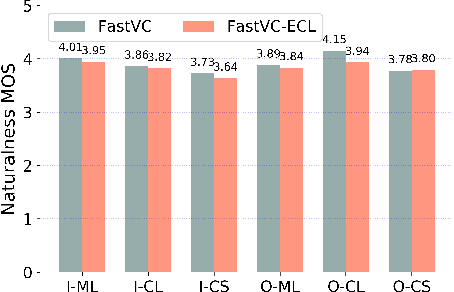
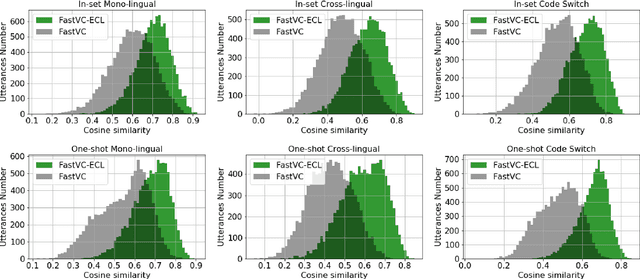
Building cross-lingual voice conversion (VC) systems for multiple speakers and multiple languages has been a challenging task for a long time. This paper describes a parallel non-autoregressive network to achieve bilingual and code-switched voice conversion for multiple speakers when there are only mono-lingual corpora for each language. We achieve cross-lingual VC between Mandarin speech with multiple speakers and English speech with multiple speakers by applying bilingual bottleneck features. To boost voice cloning performance, we use an adversarial speaker classifier with a gradient reversal layer to reduce the source speaker's information from the output of encoder. Furthermore, in order to improve speaker similarity between reference speech and converted speech, we adopt an embedding consistency loss between the synthesized speech and its natural reference speech in our network. Experimental results show that our proposed method can achieve high quality converted speech with mean opinion score (MOS) around 4. The conversion system performs well in terms of speaker similarity for both in-set speaker conversion and out-set-of one-shot conversion.