 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Single-Channel Speech for Multi-Channel End-to-End Speech Recognition: A Comparative Study
Paper and Code
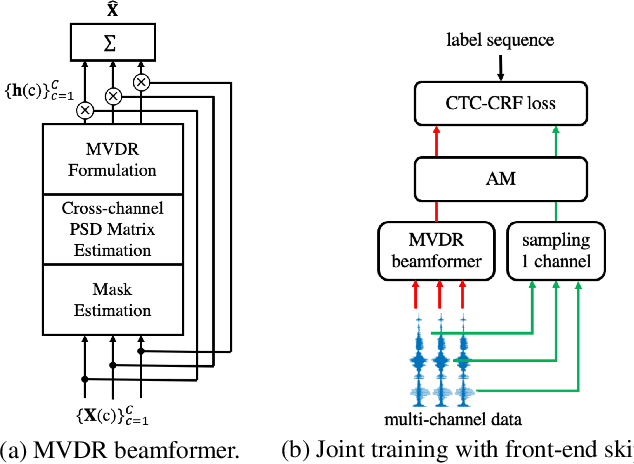

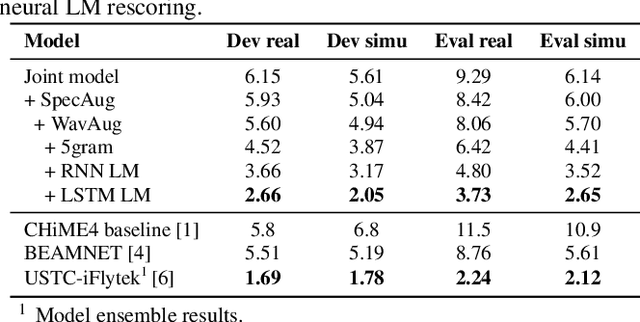
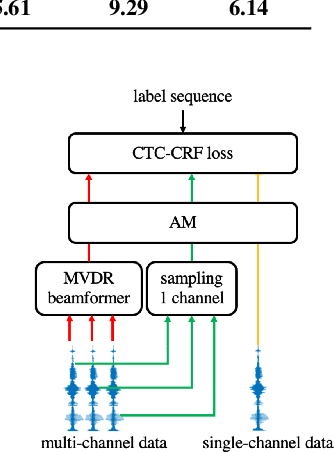
Recently, the end-to-end training approach for multi-channel ASR has shown its effectiveness, which usually consists of a beamforming front-end and a recognition back-end. However, the end-to-end training becomes more difficult due to the integration of multiple modules, particularly considering that multi-channel speech data recorded in real environments are limited in size. This raises the demand to exploit the single-channel data for multi-channel end-to-end ASR. In this paper, we systematically compare the performance of three schemes to exploit external single-channel data for multi-channel end-to-end ASR, namely back-end pre-training, data scheduling, and data simulation, under different settings such as the sizes of the single-channel data and the choices of the front-end. Extensive experiments on CHiME-4 and AISHELL-4 datasets demonstrate that while all three methods improve the multi-channel end-to-end speech recognition performance, data simulation outperforms the other two, at the cost of longer training time. Data scheduling outperforms back-end pre-training marginally but nearly consistently, presumably because that in the pre-training stage, the back-end tends to overfit on the single-channel data, especially when the single-channel data size is small.