 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Transformers in Pre-trained LM A Good ASR Encoder? An Empirical Study
Paper and Code
Sep 26, 2024

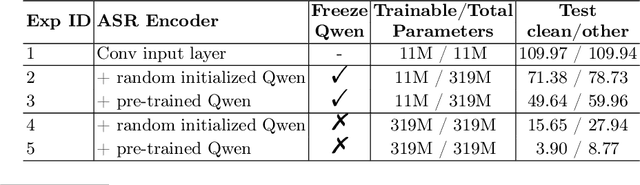

In this study, we delve into the efficacy of transformers within pre-trained language models (PLMs) when repurposed as encoders for Automatic Speech Recognition (ASR). Our underlying hypothesis posits that, despite being initially trained on text-based corpora, these transformers possess a remarkable capacity to extract effective features from the input sequence. This inherent capability, we argue, is transferrable to speech data, thereby augmenting the acoustic modeling ability of ASR. Through rigorous empirical analysis, our findings reveal a notable improvement in Character Error Rate (CER) and Word Error Rate (WER) across diverse ASR tasks when transformers from pre-trained LMs are incorporated. Particularly, they serve as an advantageous starting point for initializing ASR encoders. Furthermore, we uncover that these transformers, when integrated into a well-established ASR encoder, can significantly boost performance, especially in scenarios where profound semantic comprehension is pivotal. This underscores the potential of leveraging the semantic prowess embedded within pre-trained transformers to advance ASR systems' capabilities.