 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-SSGAN: Lifting 2D Semantics for 3D-Aware Compositional Portrait Synthesis
Paper and Code
Jan 08, 2024
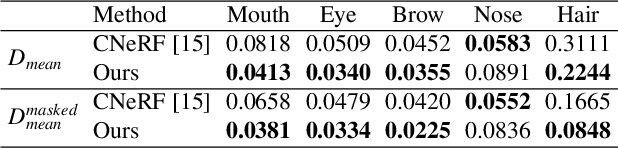
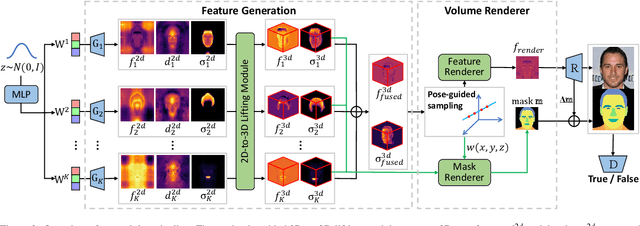

Existing 3D-aware portrait synthesis methods can generate impressive high-quality images while preserving strong 3D consistency. However, most of them cannot support the fine-grained part-level control over synthesized images. Conversely, some GAN-based 2D portrait synthesis methods can achieve clear disentanglement of facial regions, but they cannot preserve view consistency due to a lack of 3D modeling abilities. To address these issues, we propose 3D-SSGAN, a novel framework for 3D-aware compositional portrait image synthesis. First, a simple yet effective depth-guided 2D-to-3D lifting module maps the generated 2D part features and semantics to 3D. Then, a volume renderer with a novel 3D-aware semantic mask renderer is utilized to produce the composed face features and corresponding masks. The whole framework is trained end-to-end by discriminating between real and synthesized 2D images and their semantic masks. Quantitative and qualitative evaluations demonstrate the superiority of 3D-SSGAN in controllable part-level synthesis while preserving 3D view consistency.