 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Stopping Chain-of-thoughts in Large Language Models
Sep 17, 2025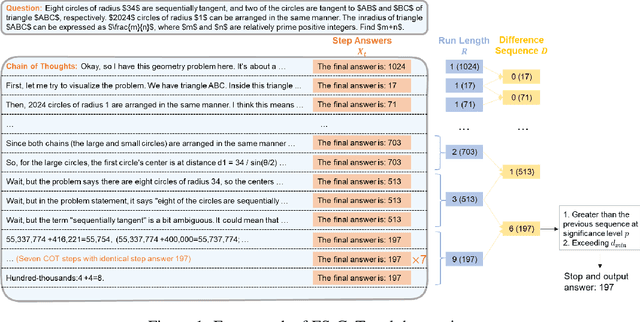
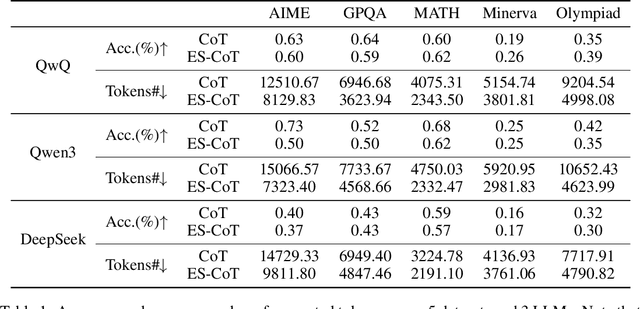
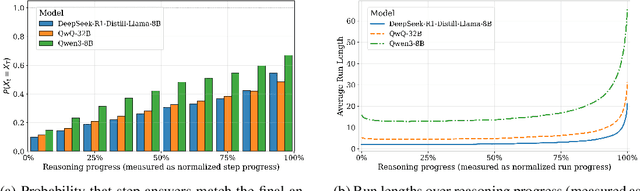
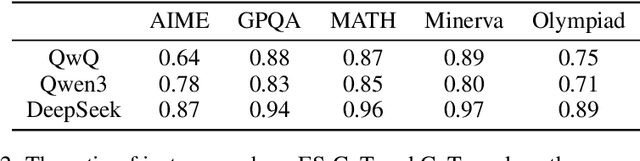
Reasoning large language models (LLMs) have demonstrated superior capacities in solving complicated problems by generating long chain-of-thoughts (CoT), but such a lengthy CoT incurs high inference costs. In this study, we introduce ES-CoT, an inference-time method that shortens CoT generation by detecting answer convergence and stopping early with minimal performance loss. At the end of each reasoning step, we prompt the LLM to output its current final answer, denoted as a step answer. We then track the run length of consecutive identical step answers as a measure of answer convergence. Once the run length exhibits a sharp increase and exceeds a minimum threshold, the generation is terminated. We provide both empirical and theoretical support for this heuristic: step answers steadily converge to the final answer, and large run-length jumps reliably mark this convergence. Experiments on five reasoning datasets across three LLMs show that ES-CoT reduces the number of inference tokens by about 41\% on average while maintaining accuracy comparable to standard CoT. Further, ES-CoT integrates seamlessly with self-consistency prompting and remains robust across hyperparameter choices, highlighting it as a practical and effective approach for efficient reasoning.
Depth Anything at Any Condition
Jul 02, 2025We present Depth Anything at Any Condition (DepthAnything-AC), a foundation monocular depth estimation (MDE) model capable of handling diverse environmental conditions. Previous foundation MDE models achieve impressive performance across general scenes but not perform well in complex open-world environments that involve challenging conditions, such as illumination variations, adverse weather, and sensor-induced distortions. To overcome the challenges of data scarcity and the inability of generating high-quality pseudo-labels from corrupted images, we propose an unsupervised consistency regularization finetuning paradigm that requires only a relatively small amount of unlabeled data. Furthermore, we propose the Spatial Distance Constraint to explicitly enforce the model to learn patch-level relative relationships, resulting in clearer semantic boundaries and more accurate details. Experimental results demonstrate the zero-shot capabilities of DepthAnything-AC across diverse benchmarks, including real-world adverse weather benchmarks, synthetic corruption benchmarks, and general benchmarks. Project Page: https://ghost233lism.github.io/depthanything-AC-page Code: https://github.com/HVision-NKU/DepthAnythingAC
DFormer: Rethinking RGBD Representation Learning for Semantic Segmentation
Sep 18, 2023



We present DFormer, a novel RGB-D pretraining framework to learn transferable representations for RGB-D segmentation tasks. DFormer has two new key innovations: 1) Unlike previous works that aim to encode RGB features,DFormer comprises a sequence of RGB-D blocks, which are tailored for encoding both RGB and depth information through a novel building block design; 2) We pre-train the backbone using image-depth pairs from ImageNet-1K, and thus the DFormer is endowed with the capacity to encode RGB-D representations. It avoids the mismatched encoding of the 3D geometry relationships in depth maps by RGB pre-trained backbones, which widely lies in existing methods but has not been resolved. We fine-tune the pre-trained DFormer on two popular RGB-D tasks, i.e., RGB-D semantic segmentation and RGB-D salient object detection, with a lightweight decoder head. Experimental results show that our DFormer achieves new state-of-the-art performance on these two tasks with less than half of the computational cost of the current best methods on two RGB-D segmentation datasets and five RGB-D saliency datasets. Our code is available at: https://github.com/VCIP-RGBD/DFormer.
Referring Camouflaged Object Detection
Jun 13, 2023



In this paper, we consider the problem of referring camouflaged object detection (Ref-COD), a new task that aims to segment specified camouflaged objects based on some form of reference, e.g., image, text. We first assemble a large-scale dataset, called R2C7K, which consists of 7K images covering 64 object categories in real-world scenarios. Then, we develop a simple but strong dual-branch framework, dubbed R2CNet, with a reference branch learning common representations from the referring information and a segmentation branch identifying and segmenting camouflaged objects under the guidance of the common representations. In particular, we design a Referring Mask Generation module to generate pixel-level prior mask and a Referring Feature Enrichment module to enhance the capability of identifying camouflaged objects. Extensive experiments show the superiority of our Ref-COD methods over their COD counterparts in segmenting specified camouflaged objects and identifying the main body of target objects. Our code and dataset are publicly available at https://github.com/zhangxuying1004/RefCOD.
CamoFormer: Masked Separable Attention for Camouflaged Object Detection
Dec 10, 2022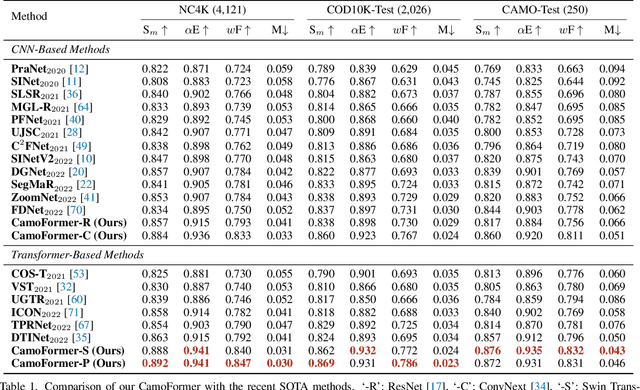
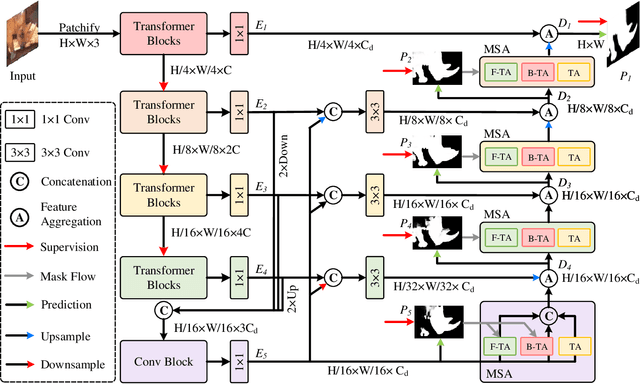
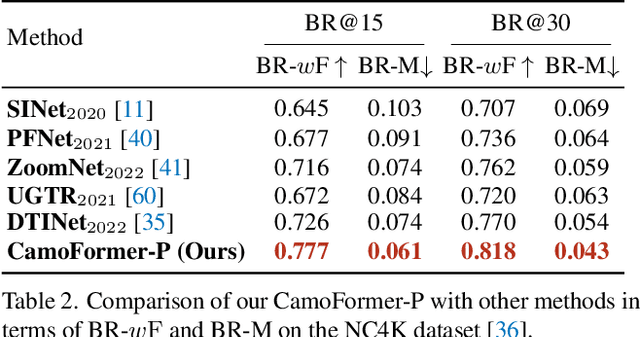
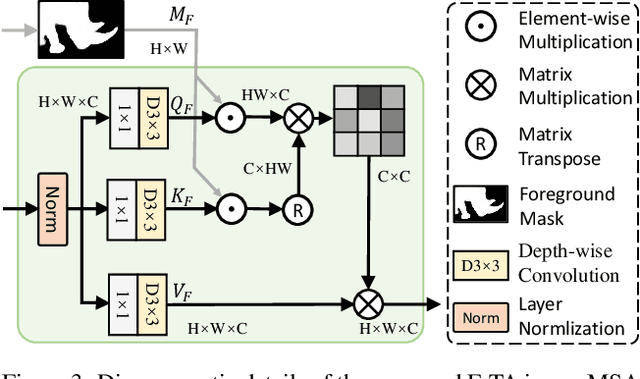
How to identify and segment camouflaged objects from the background is challenging. Inspired by the multi-head self-attention in Transformers, we present a simple masked separable attention (MSA) for camouflaged object detection. We first separate the multi-head self-attention into three parts, which are responsible for distinguishing the camouflaged objects from the background using different mask strategies. Furthermore, we propose to capture high-resolution semantic representations progressively based on a simple top-down decoder with the proposed MSA to attain precise segmentation results. These structures plus a backbone encoder form a new model, dubbed CamoFormer. Extensive experiments show that CamoFormer surpasses all existing state-of-the-art methods on three widely-used camouflaged object detection benchmarks. There are on average around 5% relative improvements over previous methods in terms of S-measure and weighted F-measure.