 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Masked Autoencoders are Stronger Vision Learners
Jul 27, 2022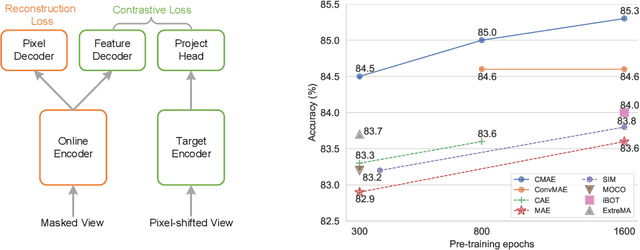

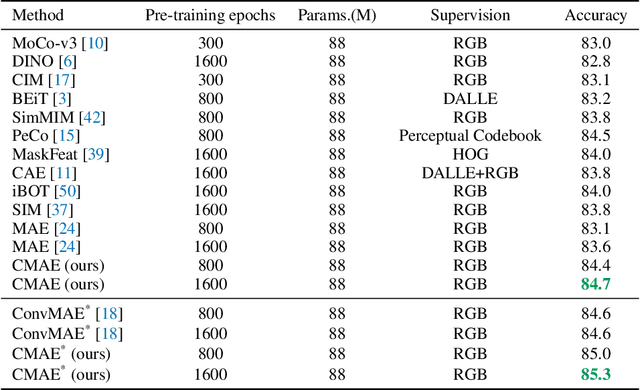
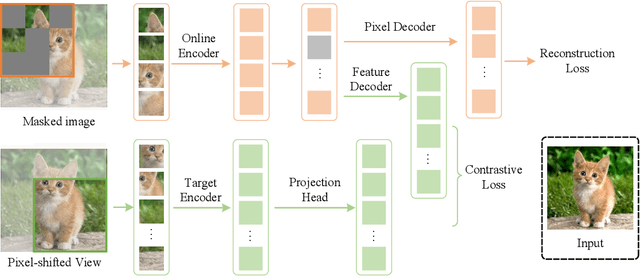
Masked image modeling (MIM) has achieved promising results on various vision tasks. However, the limited discriminability of learned representation manifests there is still plenty to go for making a stronger vision learner. Towards this goal, we propose Contrastive Masked Autoencoders (CMAE), a new self-supervised pre-training method for learning more comprehensive and capable vision representations. By elaboratively unifying contrastive learning (CL) and masked image model (MIM) through novel designs, CMAE leverages their respective advantages and learns representations with both strong instance discriminability and local perceptibility. Specifically, CMAE consists of two branches where the online branch is an asymmetric encoder-decoder and the target branch is a momentum updated encoder. During training, the online encoder reconstructs original images from latent representations of masked images to learn holistic features. The target encoder, fed with the full images, enhances the feature discriminability via contrastive learning with its online counterpart. To make CL compatible with MIM, CMAE introduces two new components, i.e. pixel shift for generating plausible positive views and feature decoder for complementing features of contrastive pairs. Thanks to these novel designs, CMAE effectively improves the representation quality and transfer performance over its MIM counterpart. CMAE achieves the state-of-the-art performance on highly competitive benchmarks of image classification, semantic segmentation and object detection. Notably, CMAE-Base achieves $85.3\%$ top-1 accuracy on ImageNet and $52.5\%$ mIoU on ADE20k, surpassing previous best results by $0.7\%$ and $1.8\%$ respectively. Codes will be made publicly available.
Highly Efficient Salient Object Detection with 100K Parameters
Mar 12, 2020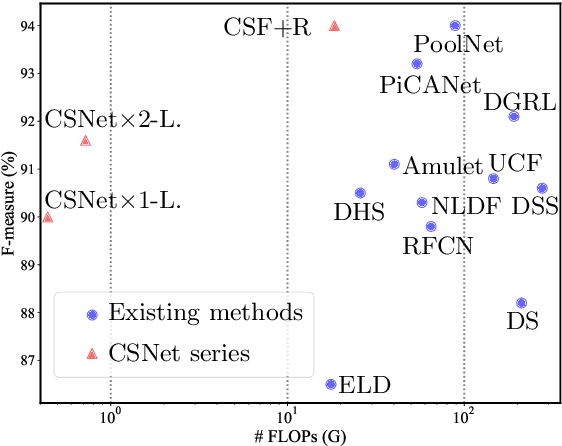
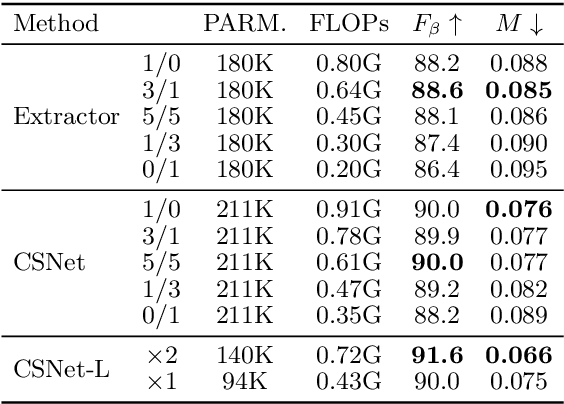
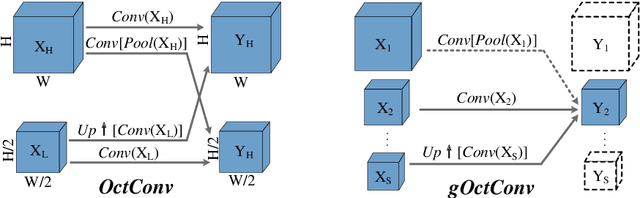
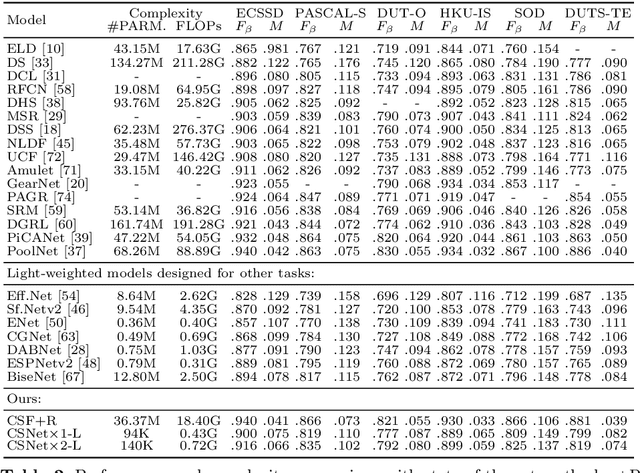
Salient object detection models often demand a considerable amount of computation cost to make precise prediction for each pixel, making them hardly applicable on low-power devices. In this paper, we aim to relieve the contradiction between computation cost and model performance by improving the network efficiency to a higher degree. We propose a flexible convolutional module, namely generalized OctConv (gOctConv), to efficiently utilize both in-stage and cross-stages multi-scale features, while reducing the representation redundancy by a novel dynamic weight decay scheme. The effective dynamic weight decay scheme stably boosts the sparsity of parameters during training, supports learnable number of channels for each scale in gOctConv, allowing 80% of parameters reduce with negligible performance drop. Utilizing gOctConv, we build an extremely light-weighted model, namely CSNet, which achieves comparable performance with about 0.2% parameters (100k) of large models on popular salient object detection benchmarks.