 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Level Contrastive Learning for Dense Prediction Task
Paper and Code
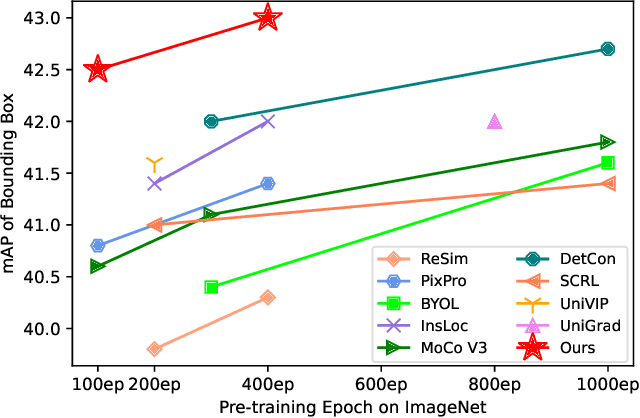
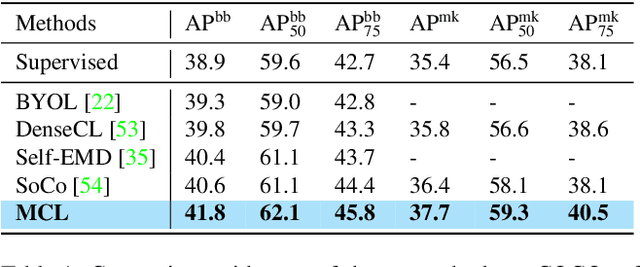
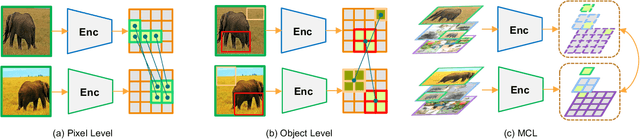
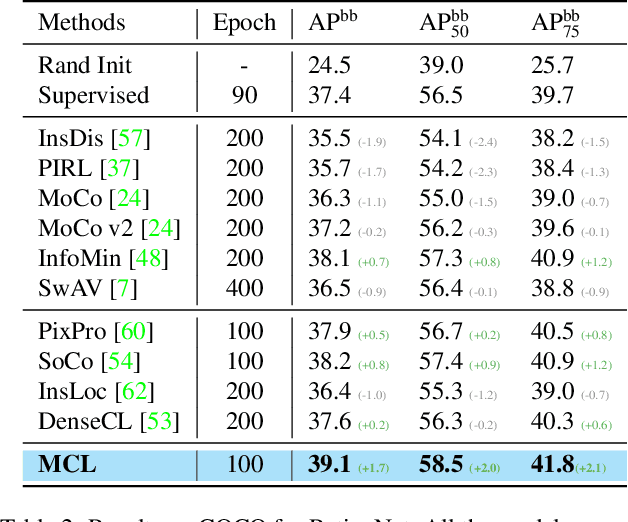
In this work, we present Multi-Level Contrastive Learning for Dense Prediction Task (MCL), an efficient self-supervised method for learning region-level feature representation for dense prediction tasks. Our method is motivated by the three key factors in detection: localization, scale consistency and recognition. To explicitly encode absolute position and scale information, we propose a novel pretext task that assembles multi-scale images in a montage manner to mimic multi-object scenarios. Unlike the existing image-level self-supervised methods, our method constructs a multi-level contrastive loss that considers each sub-region of the montage image as a singleton. Our method enables the neural network to learn regional semantic representations for translation and scale consistency while reducing pre-training epochs to the same as supervised pre-training. Extensive experiments demonstrate that MCL consistently outperforms the recent state-of-the-art methods on various datasets with significant margins. In particular, MCL obtains 42.5 AP$^\mathrm{bb}$ and 38.3 AP$^\mathrm{mk}$ on COCO with the 1x schedule fintuning, when using Mask R-CNN with R50-FPN backbone pre-trained with 100 epochs. In comparison to MoCo, our method surpasses their performance by 4.0 AP$^\mathrm{bb}$ and 3.1 AP$^\mathrm{mk}$. Furthermore, we explore the alignment between pretext task and downstream tasks. We extend our pretext task to supervised pre-training, which achieves a similar performance to self-supervised learning. This result demonstrates the importance of the alignment between pretext task and downstream tasks, indicating the potential for wider applicability of our method beyond self-supervised settings.