 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Refinement Networks for Visual Synthesis
Apr 14, 2026While diffusion models dominate the field of visual generation, they are computationally inefficient, applying a uniform computational effort regardless of different complexity. In contrast, autoregressive (AR) models are inherently complexity-aware, as evidenced by their variable likelihoods, but are often hindered by lossy discrete tokenization and error accumulation. In this work, we introduce Generative Refinement Networks (GRN), a next-generation visual synthesis paradigm to address these issues. At its core, GRN addresses the discrete tokenization bottleneck through a theoretically near-lossless Hierarchical Binary Quantization (HBQ), achieving a reconstruction quality comparable to continuous counterparts. Built upon HBQ's latent space, GRN fundamentally upgrades AR generation with a global refinement mechanism that progressively perfects and corrects artworks -- like a human artist painting. Besides, GRN integrates an entropy-guided sampling strategy, enabling complexity-aware, adaptive-step generation without compromising visual quality. On the ImageNet benchmark, GRN establishes new records in image reconstruction (0.56 rFID) and class-conditional image generation (1.81 gFID). We also scale GRN to more challenging text-to-image and text-to-video generation, delivering superior performance on an equivalent scale. We release all models and code to foster further research on GRN.
ALIVE: Animate Your World with Lifelike Audio-Video Generation
Feb 09, 2026Video generation is rapidly evolving towards unified audio-video generation. In this paper, we present ALIVE, a generation model that adapts a pretrained Text-to-Video (T2V) model to Sora-style audio-video generation and animation. In particular, the model unlocks the Text-to-Video&Audio (T2VA) and Reference-to-Video&Audio (animation) capabilities compared to the T2V foundation models. To support the audio-visual synchronization and reference animation, we augment the popular MMDiT architecture with a joint audio-video branch which includes TA-CrossAttn for temporally-aligned cross-modal fusion and UniTemp-RoPE for precise audio-visual alignment. Meanwhile, a comprehensive data pipeline consisting of audio-video captioning, quality control, etc., is carefully designed to collect high-quality finetuning data. Additionally, we introduce a new benchmark to perform a comprehensive model test and comparison. After continue pretraining and finetuning on million-level high-quality data, ALIVE demonstrates outstanding performance, consistently outperforming open-source models and matching or surpassing state-of-the-art commercial solutions. With detailed recipes and benchmarks, we hope ALIVE helps the community develop audio-video generation models more efficiently. Official page: https://github.com/FoundationVision/Alive.
InfinityStar: Unified Spacetime AutoRegressive Modeling for Visual Generation
Nov 06, 2025We introduce InfinityStar, a unified spacetime autoregressive framework for high-resolution image and dynamic video synthesis. Building on the recent success of autoregressive modeling in both vision and language, our purely discrete approach jointly captures spatial and temporal dependencies within a single architecture. This unified design naturally supports a variety of generation tasks such as text-to-image, text-to-video, image-to-video, and long interactive video synthesis via straightforward temporal autoregression. Extensive experiments demonstrate that InfinityStar scores 83.74 on VBench, outperforming all autoregressive models by large margins, even surpassing some diffusion competitors like HunyuanVideo. Without extra optimizations, our model generates a 5s, 720p video approximately 10x faster than leading diffusion-based methods. To our knowledge, InfinityStar is the first discrete autoregressive video generator capable of producing industrial level 720p videos. We release all code and models to foster further research in efficient, high-quality video generation.
Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis
Dec 05, 2024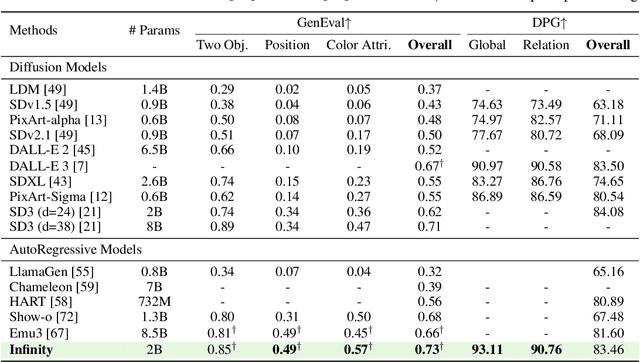

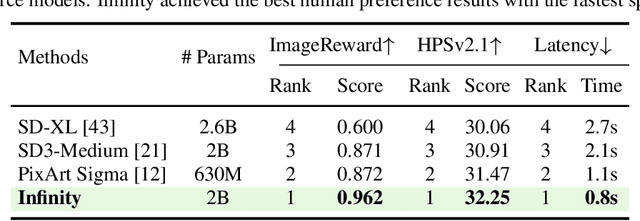

We present Infinity, a Bitwise Visual AutoRegressive Modeling capable of generating high-resolution, photorealistic images following language instruction. Infinity redefines visual autoregressive model under a bitwise token prediction framework with an infinite-vocabulary tokenizer & classifier and bitwise self-correction mechanism, remarkably improving the generation capacity and details. By theoretically scaling the tokenizer vocabulary size to infinity and concurrently scaling the transformer size, our method significantly unleashes powerful scaling capabilities compared to vanilla VAR. Infinity sets a new record for autoregressive text-to-image models, outperforming top-tier diffusion models like SD3-Medium and SDXL. Notably, Infinity surpasses SD3-Medium by improving the GenEval benchmark score from 0.62 to 0.73 and the ImageReward benchmark score from 0.87 to 0.96, achieving a win rate of 66%. Without extra optimization, Infinity generates a high-quality 1024x1024 image in 0.8 seconds, making it 2.6x faster than SD3-Medium and establishing it as the fastest text-to-image model. Models and codes will be released to promote further exploration of Infinity for visual generation and unified tokenizer modeling.
Towards Good Practices for Instance Segmentation
Oct 28, 2019
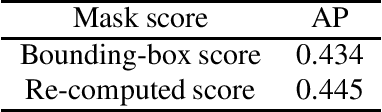


Instance Segmentation is an interesting yet challenging task in computer vision. In this paper, we conduct a series of refinements with the Hybrid Task Cascade (HTC) Network, and empirically evaluate their impact on the final model performance through ablation studies. By taking all the refinements, we achieve 0.47 on the COCO test-dev dataset and 0.47 on the COCO test-challenge dataset.
Towards Good Practices for Multi-modal Fusion in Large-scale Video Classification
Sep 28, 2018

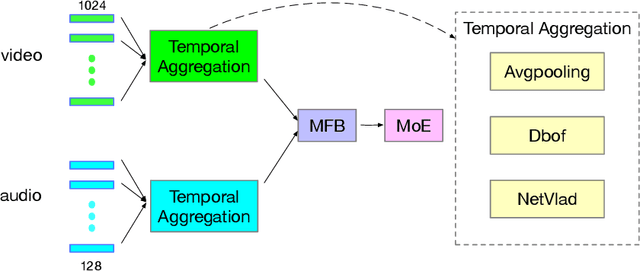

Leveraging both visual frames and audio has been experimentally proven effective to improve large-scale video classification. Previous research on video classification mainly focuses on the analysis of visual content among extracted video frames and their temporal feature aggregation. In contrast, multimodal data fusion is achieved by simple operators like average and concatenation. Inspired by the success of bilinear pooling in the visual and language fusion, we introduce multi-modal factorized bilinear pooling (MFB) to fuse visual and audio representations. We combine MFB with different video-level features and explore its effectiveness in video classification. Experimental results on the challenging Youtube-8M v2 dataset demonstrate that MFB significantly outperforms simple fusion methods in large-scale video classification.