 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Good Practices for Multi-modal Fusion in Large-scale Video Classification
Paper and Code


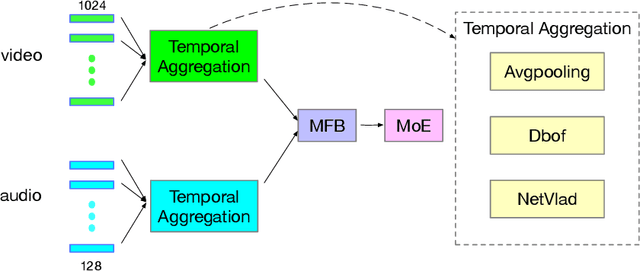

Leveraging both visual frames and audio has been experimentally proven effective to improve large-scale video classification. Previous research on video classification mainly focuses on the analysis of visual content among extracted video frames and their temporal feature aggregation. In contrast, multimodal data fusion is achieved by simple operators like average and concatenation. Inspired by the success of bilinear pooling in the visual and language fusion, we introduce multi-modal factorized bilinear pooling (MFB) to fuse visual and audio representations. We combine MFB with different video-level features and explore its effectiveness in video classification. Experimental results on the challenging Youtube-8M v2 dataset demonstrate that MFB significantly outperforms simple fusion methods in large-scale video classification.