 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural encoding and interpretation for high-level visual cortices based on fMRI using image caption features
Paper and Code


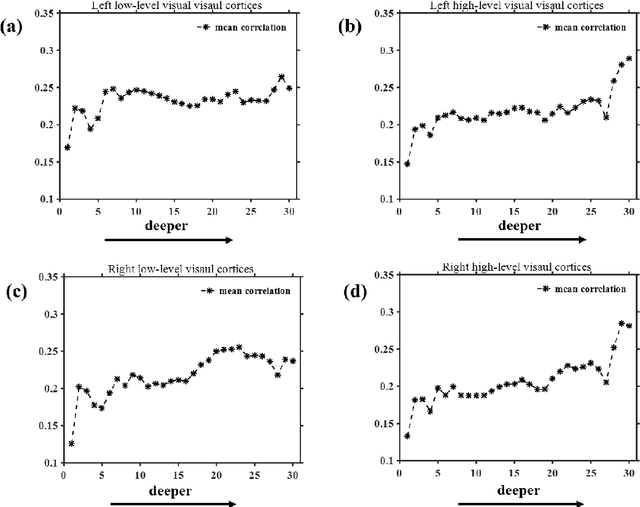

On basis of functional magnetic resonance imaging (fMRI), researchers are devoted to designing visual encoding models to predict the neuron activity of human in response to presented image stimuli and analyze inner mechanism of human visual cortices. Deep network structure composed of hierarchical processing layers forms deep network models by learning features of data on specific task through big dataset. Deep network models have powerful and hierarchical representation of data, and have brought about breakthroughs for visual encoding, while revealing hierarchical structural similarity with the manner of information processing in human visual cortices. However, previous studies almost used image features of those deep network models pre-trained on classification task to construct visual encoding models. Except for deep network structure, the task or corresponding big dataset is also important for deep network models, but neglected by previous studies. Because image classification is a relatively fundamental task, it is difficult to guide deep network models to master high-level semantic representations of data, which causes into that encoding performance for high-level visual cortices is limited. In this study, we introduced one higher-level vision task: image caption (IC) task and proposed the visual encoding model based on IC features (ICFVEM) to encode voxels of high-level visual cortices. Experiment demonstrated that ICFVEM obtained better encoding performance than previous deep network models pre-trained on classification task. In addition, the interpretation of voxels was realized to explore the detailed characteristics of voxels based on the visualization of semantic words, and comparative analysis implied that high-level visual cortices behaved the correlative representation of image content.