 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA visual encoding model based on deep neural networks and transfer learning
Feb 23, 2019



Background: Building visual encoding models to accurately predict visual responses is a central challenge for current vision-based brain-machine interface techniques. To achieve high prediction accuracy on neural signals, visual encoding models should include precise visual features and appropriate prediction algorithms. Most existing visual encoding models employ hand-craft visual features (e.g., Gabor wavelets or semantic labels) or data-driven features (e.g., features extracted from deep neural networks (DNN)). They also assume a linear mapping between feature representation to brain activity. However, it remains unknown whether such linear mapping is sufficient for maximizing prediction accuracy. New Method: We construct a new visual encoding framework to predict cortical responses in a benchmark functional magnetic resonance imaging (fMRI) dataset. In this framework, we employ the transfer learning technique to incorporate a pre-trained DNN (i.e., AlexNet) and train a nonlinear mapping from visual features to brain activity. This nonlinear mapping replaces the conventional linear mapping and is supposed to improve prediction accuracy on brain activity. Results: The proposed framework can significantly predict responses of over 20% voxels in early visual areas (i.e., V1-lateral occipital region, LO) and achieve unprecedented prediction accuracy. Comparison with Existing Methods: Comparing to two conventional visual encoding models, we find that the proposed encoding model shows consistent higher prediction accuracy in all early visual areas, especially in relatively anterior visual areas (i.e., V4 and LO). Conclusions: Our work proposes a new framework to utilize pre-trained visual features and train non-linear mappings from visual features to brain activity.
Dissociable neural representations of adversarially perturbed images in deep neural networks and the human brain
Dec 22, 2018
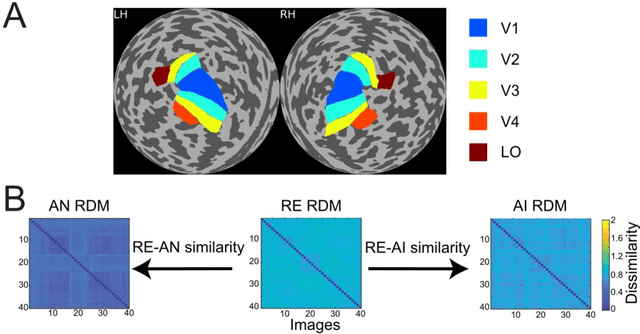
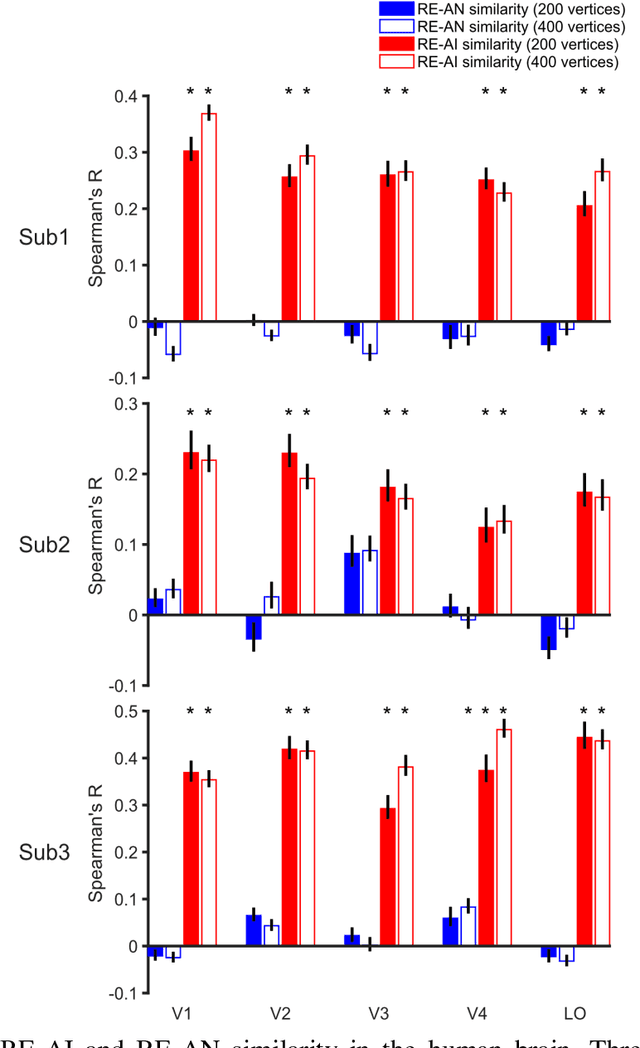
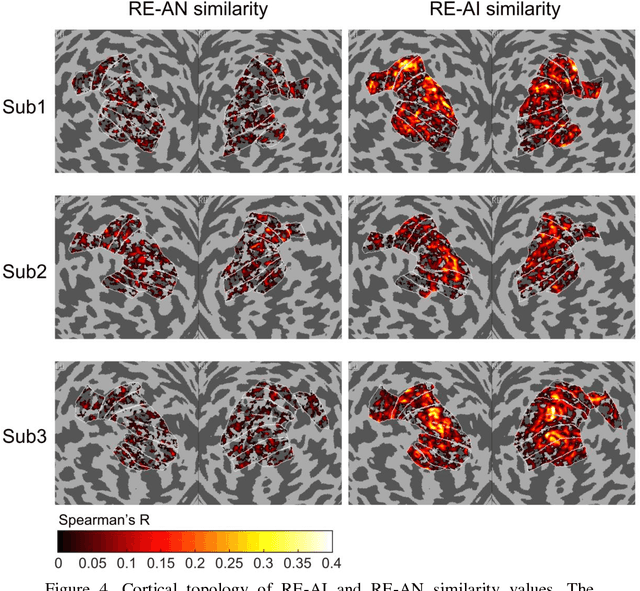
Despite the remarkable similarities between deep neural networks (DNN) and the human brain as shown in previous studies, the fact that DNNs still fall behind humans in many visual tasks suggests that considerable differences still exist between the two systems. To probe their dissimilarities, we leverage adversarial noise (AN) and adversarial interference (AI) images that yield distinct recognition performance in a prototypical DNN (AlexNet) and human vision. The evoked activity by regular (RE) and adversarial images in both systems is thoroughly compared. We find that representational similarity between RE and adversarial images in the human brain resembles their perceptual similarity. However, such representation-perception association is disrupted in the DNN. Especially, the representational similarity between RE and AN images idiosyncratically increases from low- to high-level layers. Furthermore, forward encoding modeling reveals that the DNN-brain hierarchical correspondence proposed in previous studies only holds when the two systems process RE and AI images but not AN images. These results might be due to the deterministic modeling approach of current DNNs. Taken together, our results provide a complementary perspective on the comparison between DNNs and the human brain, and highlight the need to characterize their differences to further bridge artificial and human intelligence research.