 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Non-IID Data
Paper and Code
Jun 02, 2018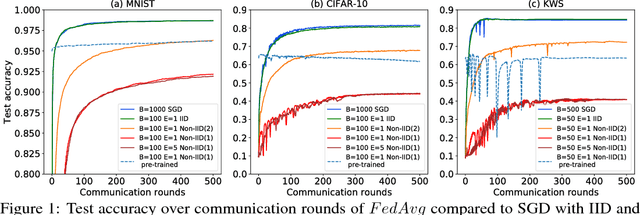
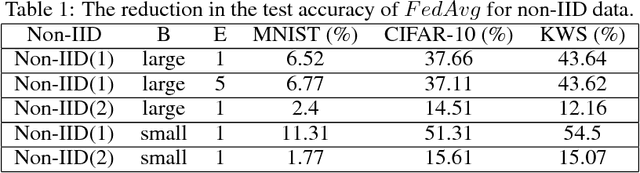
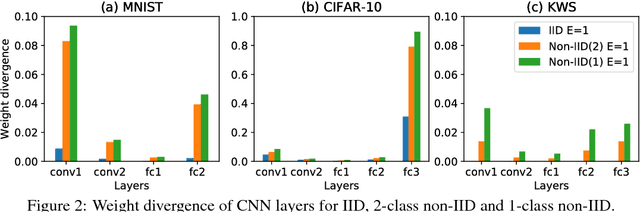
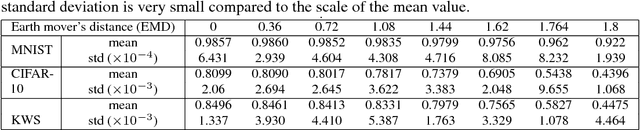
Federated learning enables resource-constrained edge compute devices, such as mobile phones and IoT devices, to learn a shared model for prediction, while keeping the training data local. This decentralized approach to train models provides privacy, security, regulatory and economic benefits. In this work, we focus on the statistical challenge of federated learning when local data is non-IID. We first show that the accuracy of federated learning reduces significantly, by up to 55% for neural networks trained for highly skewed non-IID data, where each client device trains only on a single class of data. We further show that this accuracy reduction can be explained by the weight divergence, which can be quantified by the earth mover's distance (EMD) between the distribution over classes on each device and the population distribution. As a solution, we propose a strategy to improve training on non-IID data by creating a small subset of data which is globally shared between all the edge devices. Experiments show that accuracy can be increased by 30% for the CIFAR-10 dataset with only 5% globally shared data.