 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBit Fusion: Bit-Level Dynamically Composable Architecture for Accelerating Deep Neural Networks
May 30, 2018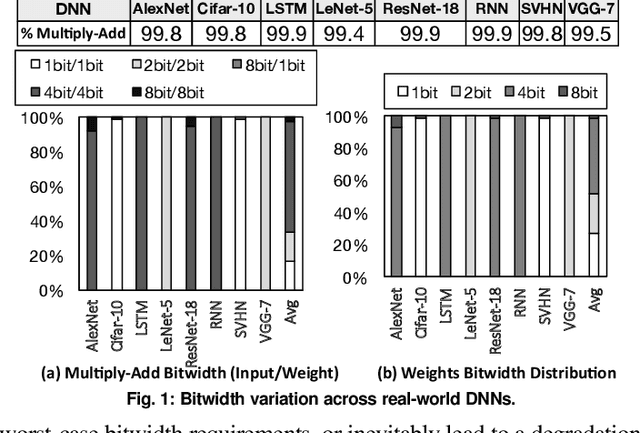
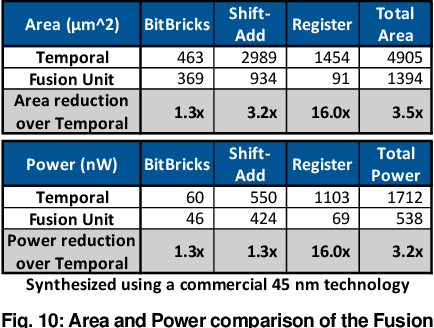
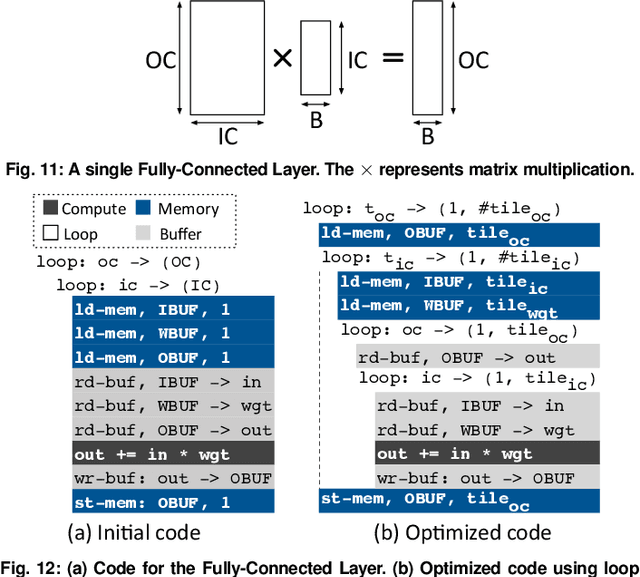
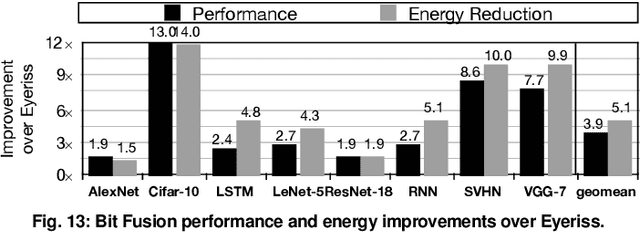
Fully realizing the potential of acceleration for Deep Neural Networks (DNNs) requires understanding and leveraging algorithmic properties. This paper builds upon the algorithmic insight that bitwidth of operations in DNNs can be reduced without compromising their classification accuracy. However, to prevent accuracy loss, the bitwidth varies significantly across DNNs and it may even be adjusted for each layer. Thus, a fixed-bitwidth accelerator would either offer limited benefits to accommodate the worst-case bitwidth requirements, or lead to a degradation in final accuracy. To alleviate these deficiencies, this work introduces dynamic bit-level fusion/decomposition as a new dimension in the design of DNN accelerators. We explore this dimension by designing Bit Fusion, a bit-flexible accelerator, that constitutes an array of bit-level processing elements that dynamically fuse to match the bitwidth of individual DNN layers. This flexibility in the architecture enables minimizing the computation and the communication at the finest granularity possible with no loss in accuracy. We evaluate the benefits of BitFusion using eight real-world feed-forward and recurrent DNNs. The proposed microarchitecture is implemented in Verilog and synthesized in 45 nm technology. Using the synthesis results and cycle accurate simulation, we compare the benefits of Bit Fusion to two state-of-the-art DNN accelerators, Eyeriss and Stripes. In the same area, frequency, and process technology, BitFusion offers 3.9x speedup and 5.1x energy savings over Eyeriss. Compared to Stripes, BitFusion provides 2.6x speedup and 3.9x energy reduction at 45 nm node when BitFusion area and frequency are set to those of Stripes. Scaling to GPU technology node of 16 nm, BitFusion almost matches the performance of a 250-Watt Titan Xp, which uses 8-bit vector instructions, while BitFusion merely consumes 895 milliwatts of power.