 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechAlign: a Framework for Speech Translation Alignment Evaluation
Paper and Code
Sep 20, 2023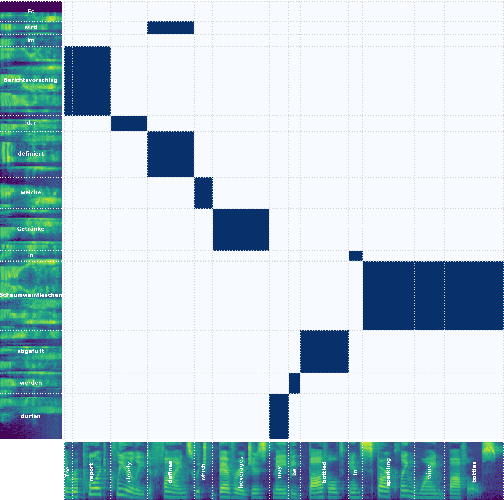

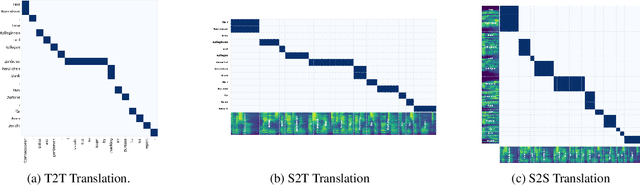
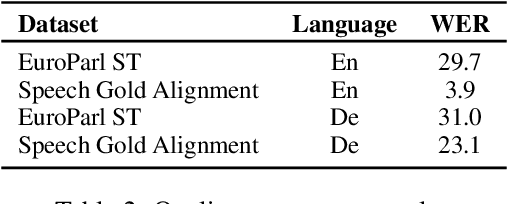
Speech-to-Speech and Speech-to-Text translation are currently dynamic areas of research. To contribute to these fields, we present SpeechAlign, a framework to evaluate the underexplored field of source-target alignment in speech models. Our framework has two core components. First, to tackle the absence of suitable evaluation datasets, we introduce the Speech Gold Alignment dataset, built upon a English-German text translation gold alignment dataset. Secondly, we introduce two novel metrics, Speech Alignment Error Rate (SAER) and Time-weighted Speech Alignment Error Rate (TW-SAER), to evaluate alignment quality in speech models. By publishing SpeechAlign we provide an accessible evaluation framework for model assessment, and we employ it to benchmark open-source Speech Translation models.