 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Spanish Emotion Recognition In-the-wild: Bringing Attention to Deep Spectrum Voice Analysis
Sep 08, 2024

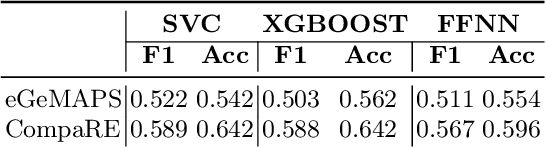

Within the context of creating new Socially Assistive Robots, emotion recognition has become a key development factor, as it allows the robot to adapt to the user's emotional state in the wild. In this work, we focused on the analysis of two voice recording Spanish datasets: ELRA-S0329 and EmoMatchSpanishDB. Specifically, we centered our work in the paralanguage, e.~g. the vocal characteristics that go along with the message and clarifies the meaning. We proposed the use of the DeepSpectrum method, which consists of extracting a visual representation of the audio tracks and feeding them to a pretrained CNN model. For the classification task, DeepSpectrum is often paired with a Support Vector Classifier --DS-SVC--, or a Fully-Connected deep-learning classifier --DS-FC--. We compared the results of the DS-SVC and DS-FC architectures with the state-of-the-art (SOTA) for ELRA-S0329 and EmoMatchSpanishDB. Moreover, we proposed our own classifier based upon Attention Mechanisms, namely DS-AM. We trained all models against both datasets, and we found that our DS-AM model outperforms the SOTA models for the datasets and the SOTA DeepSpectrum architectures. Finally, we trained our DS-AM model in one dataset and tested it in the other, to simulate real-world conditions on how biased is the model to the dataset.
Image color consistency in datasets: the Smooth-TPS3D method
Sep 08, 2024



Image color consistency is the key problem in digital imaging consistency when creating datasets. Here, we propose an improved 3D Thin-Plate Splines (TPS3D) color correction method to be used, in conjunction with color charts (i.e. Macbeth ColorChecker) or other machine-readable patterns, to achieve image consistency by post-processing. Also, we benchmark our method against its former implementation and the alternative methods reported to date with an augmented dataset based on the Gehler's ColorChecker dataset. Benchmark includes how corrected images resemble the ground-truth images and how fast these implementations are. Results demonstrate that the TPS3D is the best candidate to achieve image consistency. Furthermore, our Smooth-TPS3D method shows equivalent results compared to the original method and reduced the 11-15% of ill-conditioned scenarios which the previous method failed to less than 1%. Moreover, we demonstrate that the Smooth-TPS method is 20% faster than the original method. Finally, we discuss how different methods offer different compromises between quality, correction accuracy and computational load.
Enhancing Facial Expression Recognition through Dual-Direction Attention Mixed Feature Networks: Application to 7th ABAW Challenge
Jul 19, 2024We present our contribution to the 7th ABAW challenge at ECCV 2024, by utilizing a Dual-Direction Attention Mixed Feature Network for multitask facial expression recognition we achieve results far beyond the proposed baseline for the Multi-Task ABAW challenge. Our proposal uses the well-known DDAMFN architecture as base to effectively predict valence-arousal, emotion recognition, and action units. We demonstrate the architecture ability to handle these tasks simultaneously, providing insights into its architecture and the rationale behind its design. Additionally, we compare our results for a multitask solution with independent single-task performance.
Recognizing Emotions evoked by Movies using Multitask Learning
Jul 30, 2021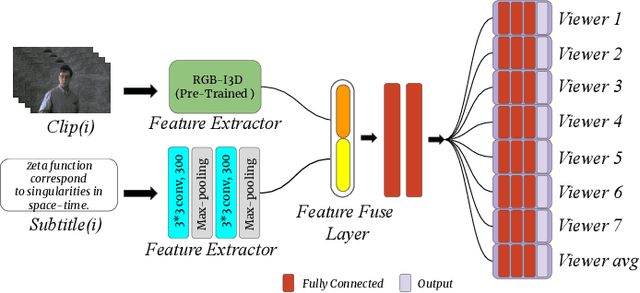
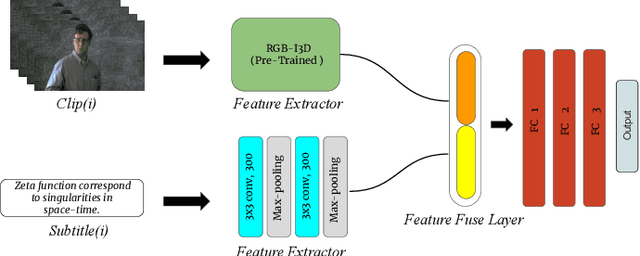
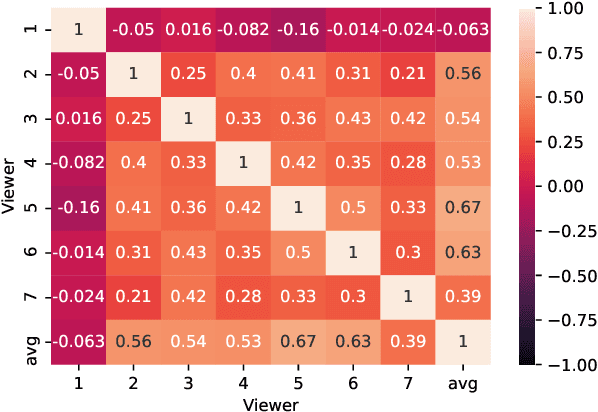
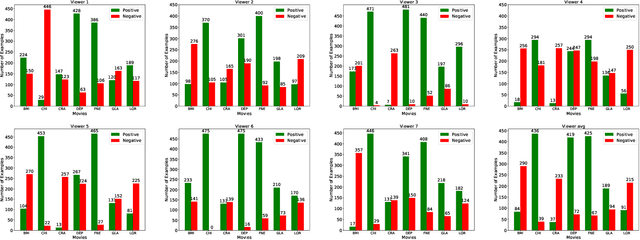
Understanding the emotional impact of movies has become important for affective movie analysis, ranking, and indexing. Methods for recognizing evoked emotions are usually trained on human annotated data. Concretely, viewers watch video clips and have to manually annotate the emotions they experienced while watching the videos. Then, the common practice is to aggregate the different annotations, by computing average scores or majority voting, and train and test models on these aggregated annotations. With this procedure a single aggregated evoked emotion annotation is obtained per each video. However, emotions experienced while watching a video are subjective: different individuals might experience different emotions. In this paper, we model the emotions evoked by videos in a different manner: instead of modeling the aggregated value we jointly model the emotions experienced by each viewer and the aggregated value using a multi-task learning approach. Concretely, we propose two deep learning architectures: a Single-Task (ST) architecture and a Multi-Task (MT) architecture. Our results show that the MT approach can more accurately model each viewer and the aggregated annotation when compared to methods that are directly trained on the aggregated annotations. Furthermore, our approach outperforms the current state-of-the-art results on the COGNIMUSE benchmark.
SynthRef: Generation of Synthetic Referring Expressions for Object Segmentation
Jun 09, 2021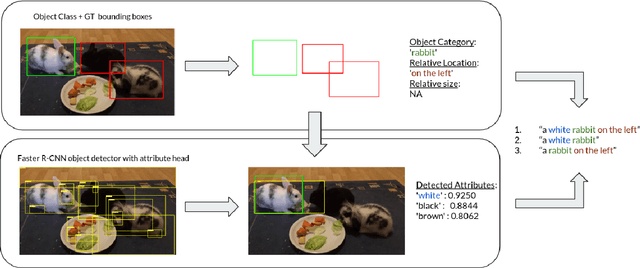



Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
RefVOS: A Closer Look at Referring Expressions for Video Object Segmentation
Oct 01, 2020

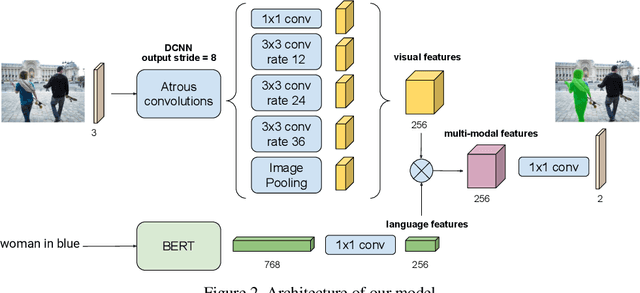
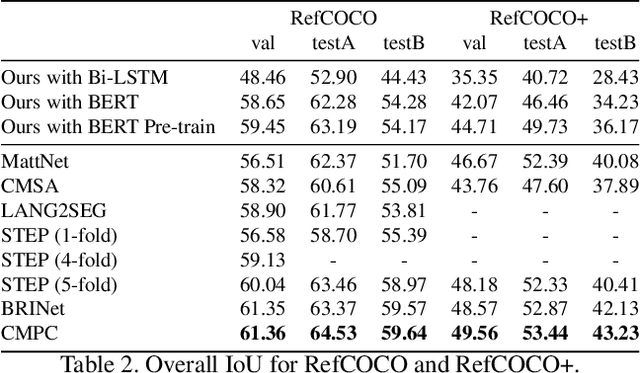
The task of video object segmentation with referring expressions (language-guided VOS) is to, given a linguistic phrase and a video, generate binary masks for the object to which the phrase refers. Our work argues that existing benchmarks used for this task are mainly composed of trivial cases, in which referents can be identified with simple phrases. Our analysis relies on a new categorization of the phrases in the DAVIS-2017 and Actor-Action datasets into trivial and non-trivial REs, with the non-trivial REs annotated with seven RE semantic categories. We leverage this data to analyze the results of RefVOS, a novel neural network that obtains competitive results for the task of language-guided image segmentation and state of the art results for language-guided VOS. Our study indicates that the major challenges for the task are related to understanding motion and static actions.
Curriculum Learning for Recurrent Video Object Segmentation
Aug 15, 2020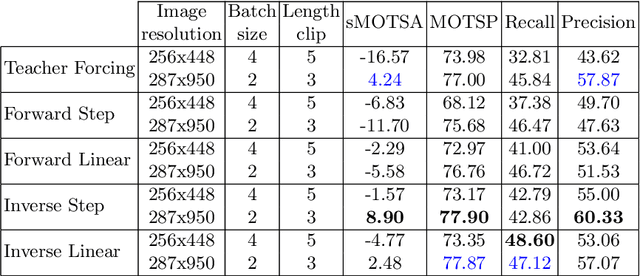

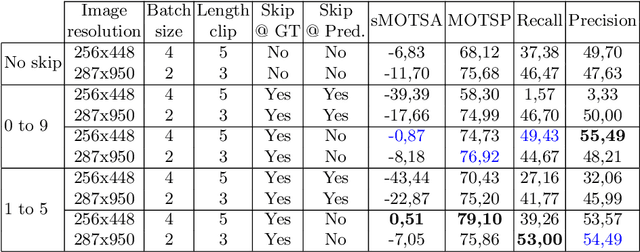
Video object segmentation can be understood as a sequence-to-sequence task that can benefit from the curriculum learning strategies for better and faster training of deep neural networks. This work explores different schedule sampling and frame skipping variations to significantly improve the performance of a recurrent architecture. Our results on the car class of the KITTI-MOTS challenge indicate that, surprisingly, an inverse schedule sampling is a better option than a classic forward one. Also, that a progressive skipping of frames during training is beneficial, but only when training with the ground truth masks instead of the predicted ones. Source code and trained models are available at http://imatge-upc.github.io/rvos-mots/.
Recurrent Instance Segmentation using Sequences of Referring Expressions
Nov 05, 2019
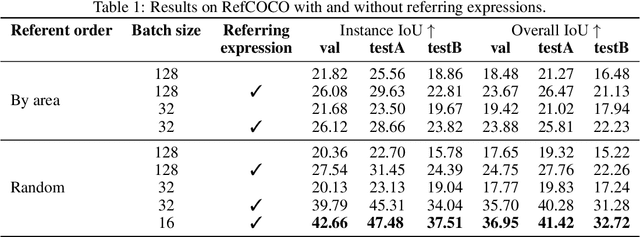
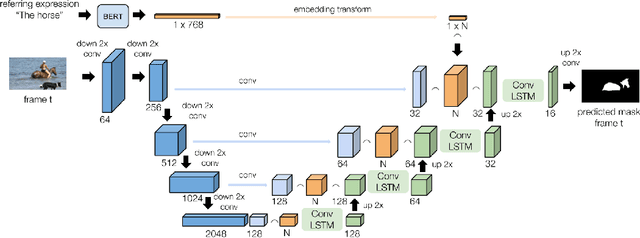

The goal of this work is to segment the objects in an image that are referred to by a sequence of linguistic descriptions (referring expressions). We propose a deep neural network with recurrent layers that output a sequence of binary masks, one for each referring expression provided by the user. The recurrent layers in the architecture allow the model to condition each predicted mask on the previous ones, from a spatial perspective within the same image. Our multimodal approach uses off-the-shelf architectures to encode both the image and the referring expressions. The visual branch provides a tensor of pixel embeddings that are concatenated with the phrase embeddings produced by a language encoder. Our experiments on the RefCOCO dataset for still images indicate how the proposed architecture successfully exploits the sequences of referring expressions to solve a pixel-wise task of instance segmentation.
RVOS: End-to-End Recurrent Network for Video Object Segmentation
Mar 13, 2019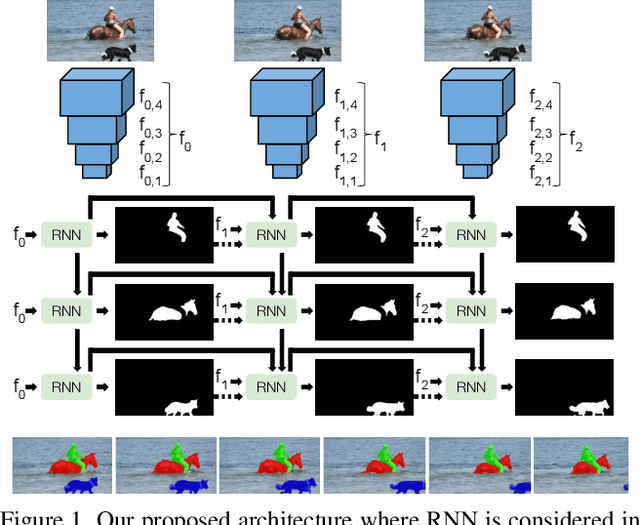
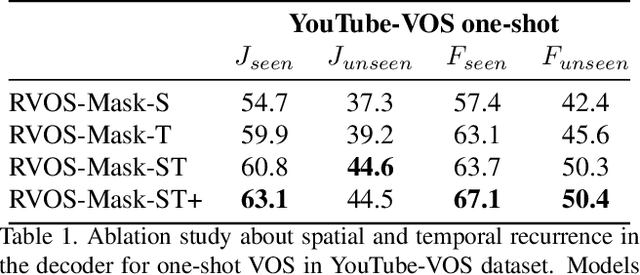
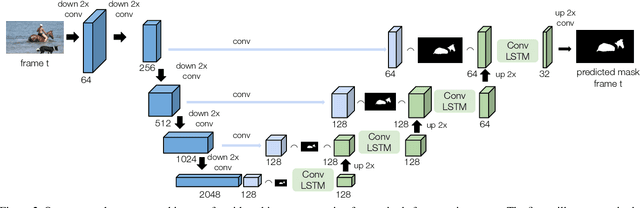
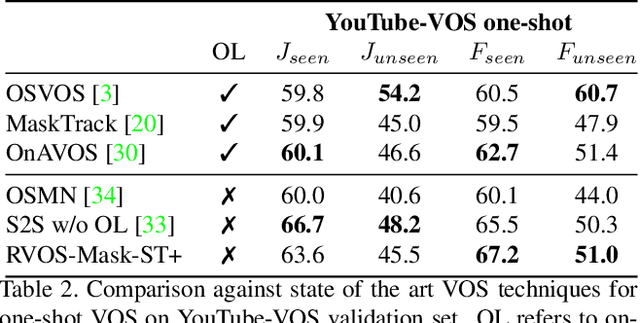
Multiple object video object segmentation is a challenging task, specially for the zero-shot case, when no object mask is given at the initial frame and the model has to find the objects to be segmented along the sequence. In our work, we propose a Recurrent network for multiple object Video Object Segmentation (RVOS) that is fully end-to-end trainable. Our model incorporates recurrence on two different domains: (i) the spatial, which allows to discover the different object instances within a frame, and (ii) the temporal, which allows to keep the coherence of the segmented objects along time. We train RVOS for zero-shot video object segmentation and are the first ones to report quantitative results for DAVIS-2017 and YouTube-VOS benchmarks. Further, we adapt RVOS for one-shot video object segmentation by using the masks obtained in previous time steps as inputs to be processed by the recurrent module. Our model reaches comparable results to state-of-the-art techniques in YouTube-VOS benchmark and outperforms all previous video object segmentation methods not using online learning in the DAVIS-2017 benchmark. Moreover, our model achieves faster inference runtimes than previous methods, reaching 44ms/frame on a P100 GPU.
Iterative Deep Learning for Road Topology Extraction
Aug 28, 2018
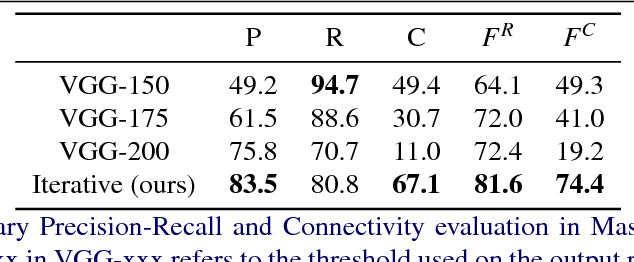

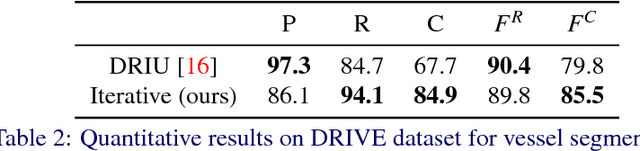
This paper tackles the task of estimating the topology of road networks from aerial images. Building on top of a global model that performs a dense semantical classification of the pixels of the image, we design a Convolutional Neural Network (CNN) that predicts the local connectivity among the central pixel of an input patch and its border points. By iterating this local connectivity we sweep the whole image and infer the global topology of the road network, inspired by a human delineating a complex network with the tip of their finger. We perform an extensive and comprehensive qualitative and quantitative evaluation on the road network estimation task, and show that our method also generalizes well when moving to networks of retinal vessels.