 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthRef: Generation of Synthetic Referring Expressions for Object Segmentation
Jun 09, 2021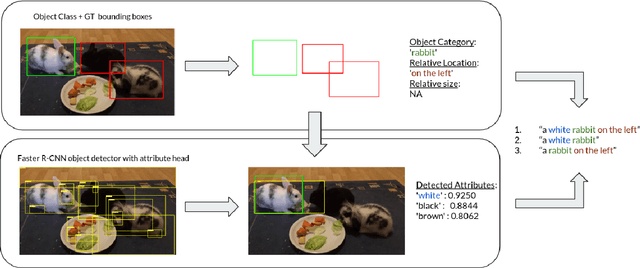



Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
RefVOS: A Closer Look at Referring Expressions for Video Object Segmentation
Oct 01, 2020

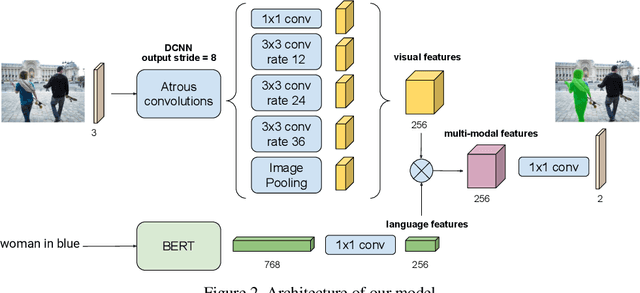
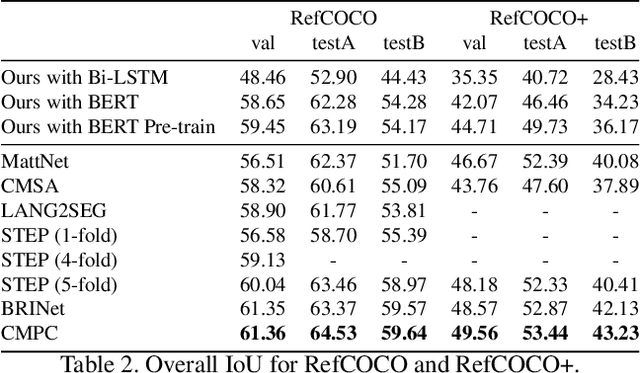
The task of video object segmentation with referring expressions (language-guided VOS) is to, given a linguistic phrase and a video, generate binary masks for the object to which the phrase refers. Our work argues that existing benchmarks used for this task are mainly composed of trivial cases, in which referents can be identified with simple phrases. Our analysis relies on a new categorization of the phrases in the DAVIS-2017 and Actor-Action datasets into trivial and non-trivial REs, with the non-trivial REs annotated with seven RE semantic categories. We leverage this data to analyze the results of RefVOS, a novel neural network that obtains competitive results for the task of language-guided image segmentation and state of the art results for language-guided VOS. Our study indicates that the major challenges for the task are related to understanding motion and static actions.