 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe iToBoS dataset: skin region images extracted from 3D total body photographs for lesion detection
Jan 30, 2025



Artificial intelligence has significantly advanced skin cancer diagnosis by enabling rapid and accurate detection of malignant lesions. In this domain, most publicly available image datasets consist of single, isolated skin lesions positioned at the center of the image. While these lesion-centric datasets have been fundamental for developing diagnostic algorithms, they lack the context of the surrounding skin, which is critical for improving lesion detection. The iToBoS dataset was created to address this challenge. It includes 16,954 images of skin regions from 100 participants, captured using 3D total body photography. Each image roughly corresponds to a $7 \times 9$ cm section of skin with all suspicious lesions annotated using bounding boxes. Additionally, the dataset provides metadata such as anatomical location, age group, and sun damage score for each image. This dataset aims to facilitate training and benchmarking of algorithms, with the goal of enabling early detection of skin cancer and deployment of this technology in non-clinical environments.
Recognizing Emotions evoked by Movies using Multitask Learning
Jul 30, 2021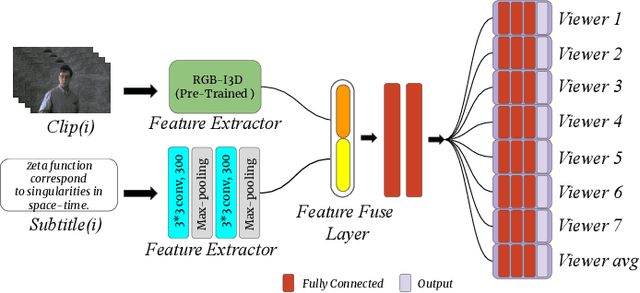
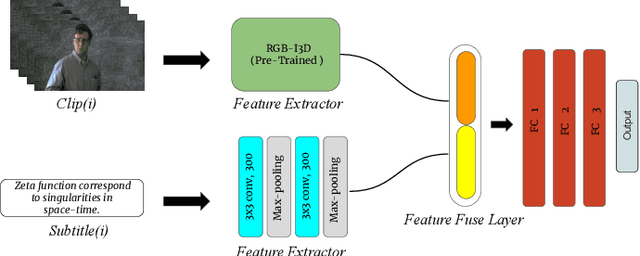
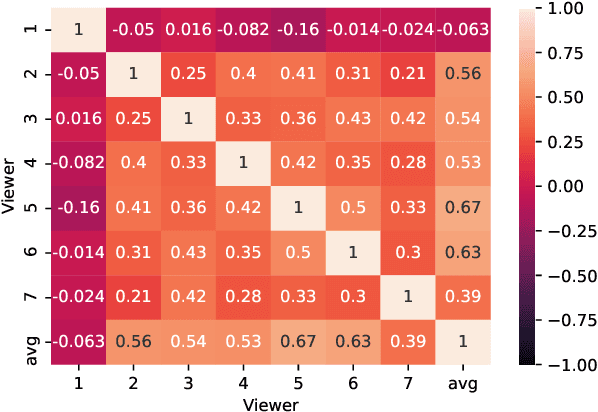
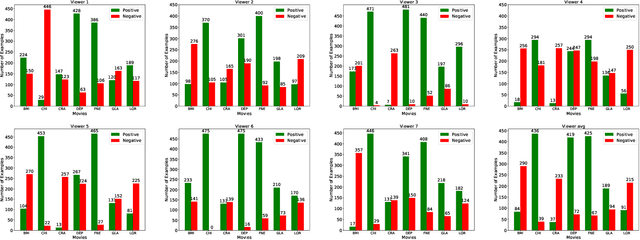
Understanding the emotional impact of movies has become important for affective movie analysis, ranking, and indexing. Methods for recognizing evoked emotions are usually trained on human annotated data. Concretely, viewers watch video clips and have to manually annotate the emotions they experienced while watching the videos. Then, the common practice is to aggregate the different annotations, by computing average scores or majority voting, and train and test models on these aggregated annotations. With this procedure a single aggregated evoked emotion annotation is obtained per each video. However, emotions experienced while watching a video are subjective: different individuals might experience different emotions. In this paper, we model the emotions evoked by videos in a different manner: instead of modeling the aggregated value we jointly model the emotions experienced by each viewer and the aggregated value using a multi-task learning approach. Concretely, we propose two deep learning architectures: a Single-Task (ST) architecture and a Multi-Task (MT) architecture. Our results show that the MT approach can more accurately model each viewer and the aggregated annotation when compared to methods that are directly trained on the aggregated annotations. Furthermore, our approach outperforms the current state-of-the-art results on the COGNIMUSE benchmark.