 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegotron: Regularizing the Tacotron2 architecture via monotonic alignment loss
Paper and Code
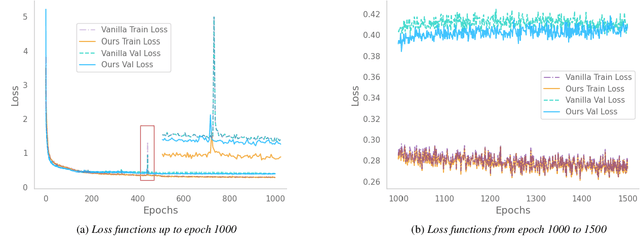
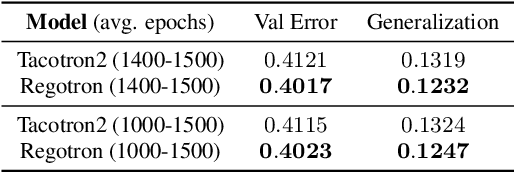
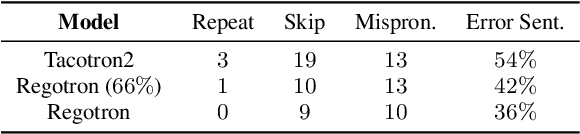
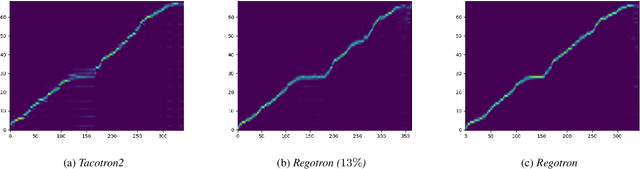
Recent deep learning Text-to-Speech (TTS) systems have achieved impressive performance by generating speech close to human parity. However, they suffer from training stability issues as well as incorrect alignment of the intermediate acoustic representation with the input text sequence. In this work, we introduce Regotron, a regularized version of Tacotron2 which aims to alleviate the training issues and at the same time produce monotonic alignments. Our method augments the vanilla Tacotron2 objective function with an additional term, which penalizes non-monotonic alignments in the location-sensitive attention mechanism. By properly adjusting this regularization term we show that the loss curves become smoother, and at the same time Regotron consistently produces monotonic alignments in unseen examples even at an early stage (13\% of the total number of epochs) of its training process, whereas the fully converged Tacotron2 fails to do so. Moreover, our proposed regularization method has no additional computational overhead, while reducing common TTS mistakes and achieving slighlty improved speech naturalness according to subjective mean opinion scores (MOS) collected from 50 evaluators.