 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Hidden Biases in Text-to-Image Models via Automated Prompt Search
Dec 09, 2025Text-to-image (TTI) diffusion models have achieved remarkable visual quality, yet they have been repeatedly shown to exhibit social biases across sensitive attributes such as gender, race and age. To mitigate these biases, existing approaches frequently depend on curated prompt datasets - either manually constructed or generated with large language models (LLMs) - as part of their training and/or evaluation procedures. Beside the curation cost, this also risks overlooking unanticipated, less obvious prompts that trigger biased generation, even in models that have undergone debiasing. In this work, we introduce Bias-Guided Prompt Search (BGPS), a framework that automatically generates prompts that aim to maximize the presence of biases in the resulting images. BGPS comprises two components: (1) an LLM instructed to produce attribute-neutral prompts and (2) attribute classifiers acting on the TTI's internal representations that steer the decoding process of the LLM toward regions of the prompt space that amplify the image attributes of interest. We conduct extensive experiments on Stable Diffusion 1.5 and a state-of-the-art debiased model and discover an array of subtle and previously undocumented biases that severely deteriorate fairness metrics. Crucially, the discovered prompts are interpretable, i.e they may be entered by a typical user, quantitatively improving the perplexity metric compared to a prominent hard prompt optimization counterpart. Our findings uncover TTI vulnerabilities, while BGPS expands the bias search space and can act as a new evaluation tool for bias mitigation.
Enabling Local Editing in Diffusion Models by Joint and Individual Component Analysis
Sep 02, 2024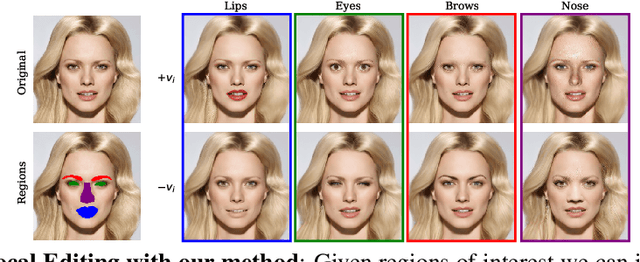

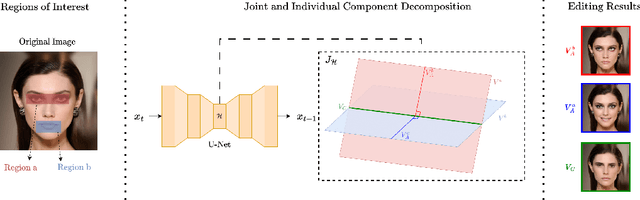

Recent advances in Diffusion Models (DMs) have led to significant progress in visual synthesis and editing tasks, establishing them as a strong competitor to Generative Adversarial Networks (GANs). However, the latent space of DMs is not as well understood as that of GANs. Recent research has focused on unsupervised semantic discovery in the latent space of DMs by leveraging the bottleneck layer of the denoising network, which has been shown to exhibit properties of a semantic latent space. However, these approaches are limited to discovering global attributes. In this paper we address, the challenge of local image manipulation in DMs and introduce an unsupervised method to factorize the latent semantics learned by the denoising network of pre-trained DMs. Given an arbitrary image and defined regions of interest, we utilize the Jacobian of the denoising network to establish a relation between the regions of interest and their corresponding subspaces in the latent space. Furthermore, we disentangle the joint and individual components of these subspaces to identify latent directions that enable local image manipulation. Once discovered, these directions can be applied to different images to produce semantically consistent edits, making our method suitable for practical applications. Experimental results on various datasets demonstrate that our method can produce semantic edits that are more localized and have better fidelity compared to the state-of-the-art.
Investigating Personalization Methods in Text to Music Generation
Sep 20, 2023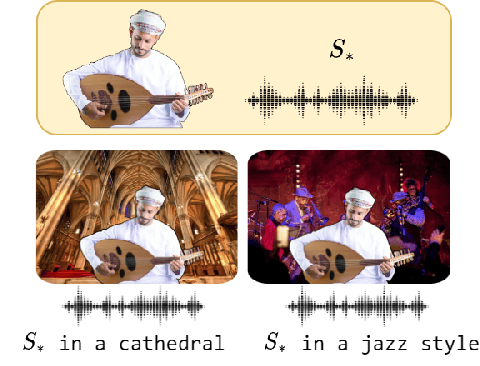
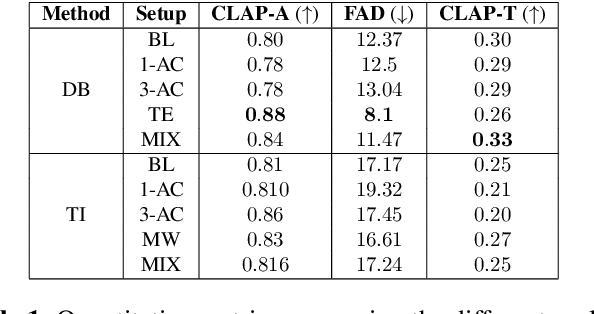
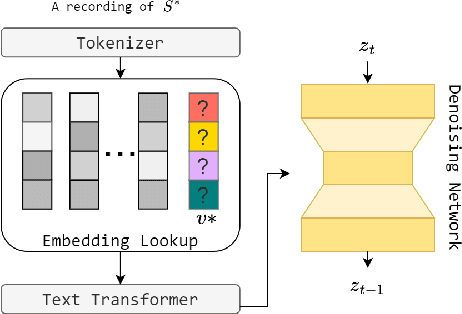
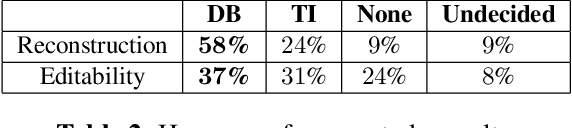
In this work, we investigate the personalization of text-to-music diffusion models in a few-shot setting. Motivated by recent advances in the computer vision domain, we are the first to explore the combination of pre-trained text-to-audio diffusers with two established personalization methods. We experiment with the effect of audio-specific data augmentation on the overall system performance and assess different training strategies. For evaluation, we construct a novel dataset with prompts and music clips. We consider both embedding-based and music-specific metrics for quantitative evaluation, as well as a user study for qualitative evaluation. Our analysis shows that similarity metrics are in accordance with user preferences and that current personalization approaches tend to learn rhythmic music constructs more easily than melody. The code, dataset, and example material of this study are open to the research community.
Zero-Shot Cross-lingual Aphasia Detection using Automatic Speech Recognition
Apr 01, 2022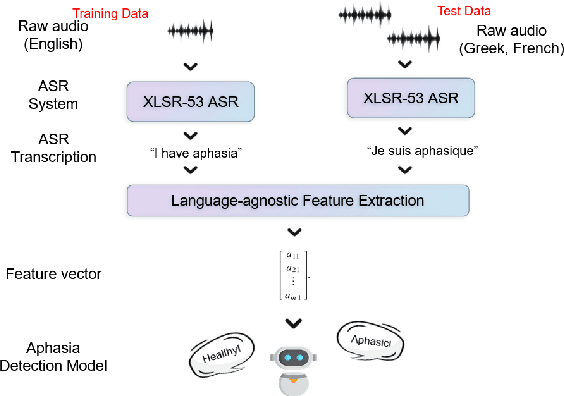
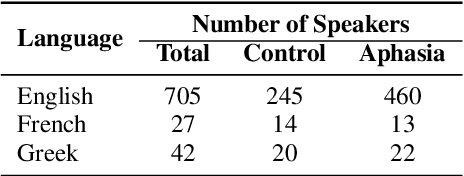
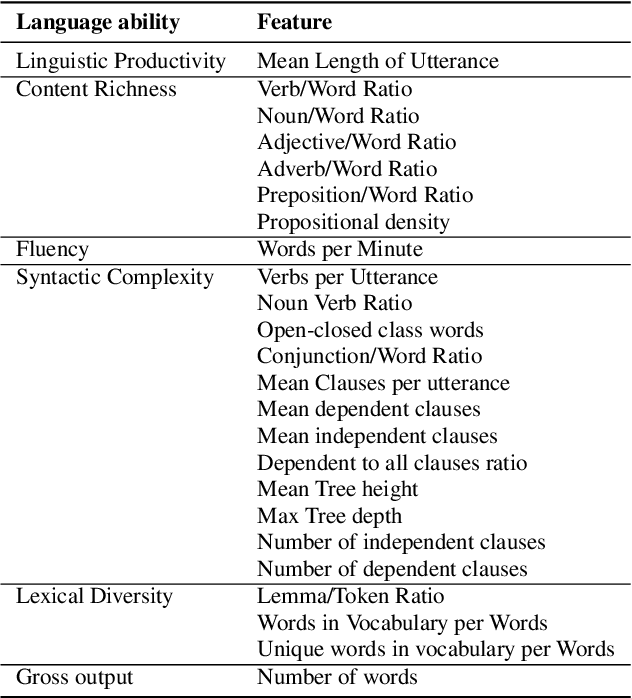
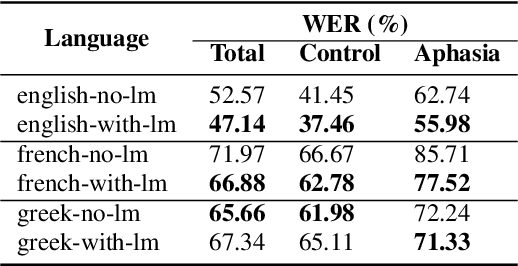
Aphasia is a common speech and language disorder, typically caused by a brain injury or a stroke, that affects millions of people worldwide. Detecting and assessing Aphasia in patients is a difficult, time-consuming process, and numerous attempts to automate it have been made, the most successful using machine learning models trained on aphasic speech data. Like in many medical applications, aphasic speech data is scarce and the problem is exacerbated in so-called "low resource" languages, which are, for this task, most languages excluding English. We attempt to leverage available data in English and achieve zero-shot aphasia detection in low-resource languages such as Greek and French, by using language-agnostic linguistic features. Current cross-lingual aphasia detection approaches rely on manually extracted transcripts. We propose an end-to-end pipeline using pre-trained Automatic Speech Recognition (ASR) models that share cross-lingual speech representations and are fine-tuned for our desired low-resource languages. To further boost our ASR model's performance, we also combine it with a language model. We show that our ASR-based end-to-end pipeline offers comparable results to previous setups using human-annotated transcripts.