 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVLMs and Humans Ground Differently in Referential Communication
Jan 28, 2026For generative AI agents to partner effectively with human users, the ability to accurately predict human intent is critical. But this ability to collaborate remains limited by a critical deficit: an inability to model common ground. Here, we present a referential communication experiment with a factorial design involving director-matcher pairs (human-human, human-AI, AI-human, and AI-AI) that interact with multiple turns in repeated rounds to match pictures of objects not associated with any obvious lexicalized labels. We release the online pipeline for data collection, the tools and analyses for accuracy, efficiency, and lexical overlap, and a corpus of 356 dialogues (89 pairs over 4 rounds each) that unmasks LVLMs' limitations in interactively resolving referring expressions, a crucial skill that underlies human language use.
Learning to Align: Addressing Character Frequency Distribution Shifts in Handwritten Text Recognition
Jun 11, 2025Handwritten text recognition aims to convert visual input into machine-readable text, and it remains challenging due to the evolving and context-dependent nature of handwriting. Character sets change over time, and character frequency distributions shift across historical periods or regions, often causing models trained on broad, heterogeneous corpora to underperform on specific subsets. To tackle this, we propose a novel loss function that incorporates the Wasserstein distance between the character frequency distribution of the predicted text and a target distribution empirically derived from training data. By penalizing divergence from expected distributions, our approach enhances both accuracy and robustness under temporal and contextual intra-dataset shifts. Furthermore, we demonstrate that character distribution alignment can also improve existing models at inference time without requiring retraining by integrating it as a scoring function in a guided decoding scheme. Experimental results across multiple datasets and architectures confirm the effectiveness of our method in boosting generalization and performance. We open source our code at https://github.com/pkaliosis/fada.
Improving Contrastive Learning for Referring Expression Counting
May 28, 2025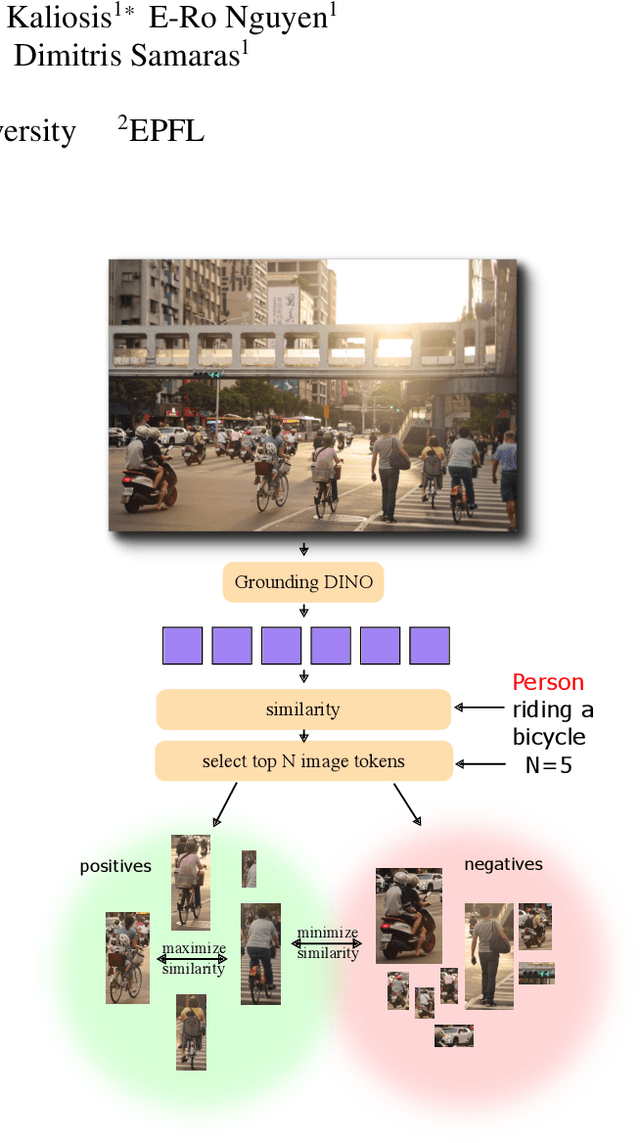
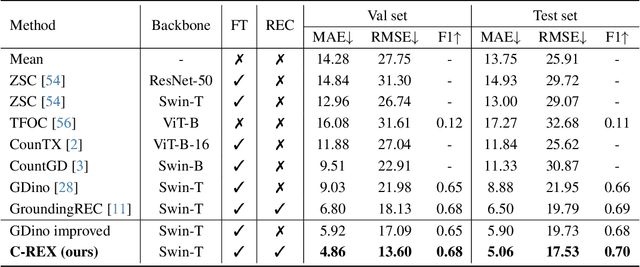

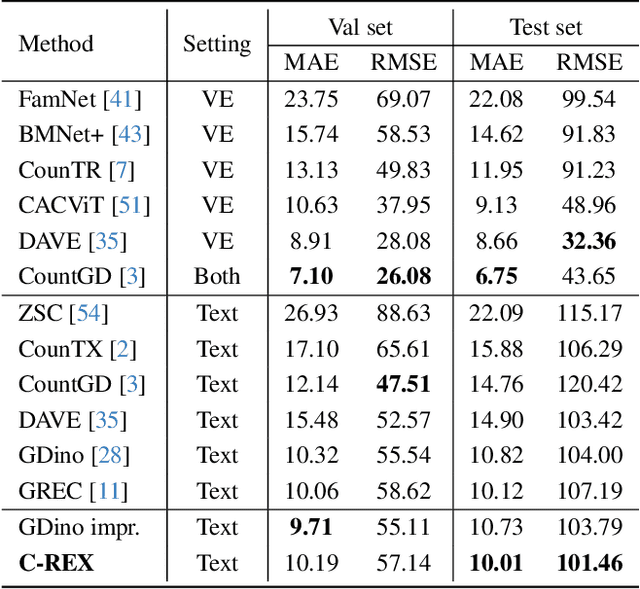
Object counting has progressed from class-specific models, which count only known categories, to class-agnostic models that generalize to unseen categories. The next challenge is Referring Expression Counting (REC), where the goal is to count objects based on fine-grained attributes and contextual differences. Existing methods struggle with distinguishing visually similar objects that belong to the same category but correspond to different referring expressions. To address this, we propose C-REX, a novel contrastive learning framework, based on supervised contrastive learning, designed to enhance discriminative representation learning. Unlike prior works, C-REX operates entirely within the image space, avoiding the misalignment issues of image-text contrastive learning, thus providing a more stable contrastive signal. It also guarantees a significantly larger pool of negative samples, leading to improved robustness in the learned representations. Moreover, we showcase that our framework is versatile and generic enough to be applied to other similar tasks like class-agnostic counting. To support our approach, we analyze the key components of sota detection-based models and identify that detecting object centroids instead of bounding boxes is the key common factor behind their success in counting tasks. We use this insight to design a simple yet effective detection-based baseline to build upon. Our experiments show that C-REX achieves state-of-the-art results in REC, outperforming previous methods by more than 22\% in MAE and more than 10\% in RMSE, while also demonstrating strong performance in class-agnostic counting. Code is available at https://github.com/cvlab-stonybrook/c-rex.
Greek2MathTex: A Greek Speech-to-Text Framework for LaTeX Equations Generation
Dec 11, 2024In the vast majority of the academic and scientific domains, LaTeX has established itself as the de facto standard for typesetting complex mathematical equations and formulae. However, LaTeX's complex syntax and code-like appearance present accessibility barriers for individuals with disabilities, as well as those unfamiliar with coding conventions. In this paper, we present a novel solution to this challenge through the development of a novel speech-to-LaTeX equations system specifically designed for the Greek language. We propose an end-to-end system that harnesses the power of Automatic Speech Recognition (ASR) and Natural Language Processing (NLP) techniques to enable users to verbally dictate mathematical expressions and equations in natural language, which are subsequently converted into LaTeX format. We present the architecture and design principles of our system, highlighting key components such as the ASR engine, the LLM-based prompt-driven equations generation mechanism, as well as the application of a custom evaluation metric employed throughout the development process. We have made our system open source and available at https://github.com/magcil/greek-speech-to-math.
A Data-Driven Guided Decoding Mechanism for Diagnostic Captioning
Jun 20, 2024



Diagnostic Captioning (DC) automatically generates a diagnostic text from one or more medical images (e.g., X-rays, MRIs) of a patient. Treated as a draft, the generated text may assist clinicians, by providing an initial estimation of the patient's condition, speeding up and helping safeguard the diagnostic process. The accuracy of a diagnostic text, however, strongly depends on how well the key medical conditions depicted in the images are expressed. We propose a new data-driven guided decoding method that incorporates medical information, in the form of existing tags capturing key conditions of the image(s), into the beam search of the diagnostic text generation process. We evaluate the proposed method on two medical datasets using four DC systems that range from generic image-to-text systems with CNN encoders and RNN decoders to pre-trained Large Language Models. The latter can also be used in few- and zero-shot learning scenarios. In most cases, the proposed mechanism improves performance with respect to all evaluation measures. We provide an open-source implementation of the proposed method at https://github.com/nlpaueb/dmmcs.