 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel Motion Diffusion is What We Need for Robot Control
Sep 26, 2025We present DAWN (Diffusion is All We Need for robot control), a unified diffusion-based framework for language-conditioned robotic manipulation that bridges high-level motion intent and low-level robot action via structured pixel motion representation. In DAWN, both the high-level and low-level controllers are modeled as diffusion processes, yielding a fully trainable, end-to-end system with interpretable intermediate motion abstractions. DAWN achieves state-of-the-art results on the challenging CALVIN benchmark, demonstrating strong multi-task performance, and further validates its effectiveness on MetaWorld. Despite the substantial domain gap between simulation and reality and limited real-world data, we demonstrate reliable real-world transfer with only minimal finetuning, illustrating the practical viability of diffusion-based motion abstractions for robotic control. Our results show the effectiveness of combining diffusion modeling with motion-centric representations as a strong baseline for scalable and robust robot learning. Project page: https://nero1342.github.io/DAWN/
Improving Contrastive Learning for Referring Expression Counting
May 28, 2025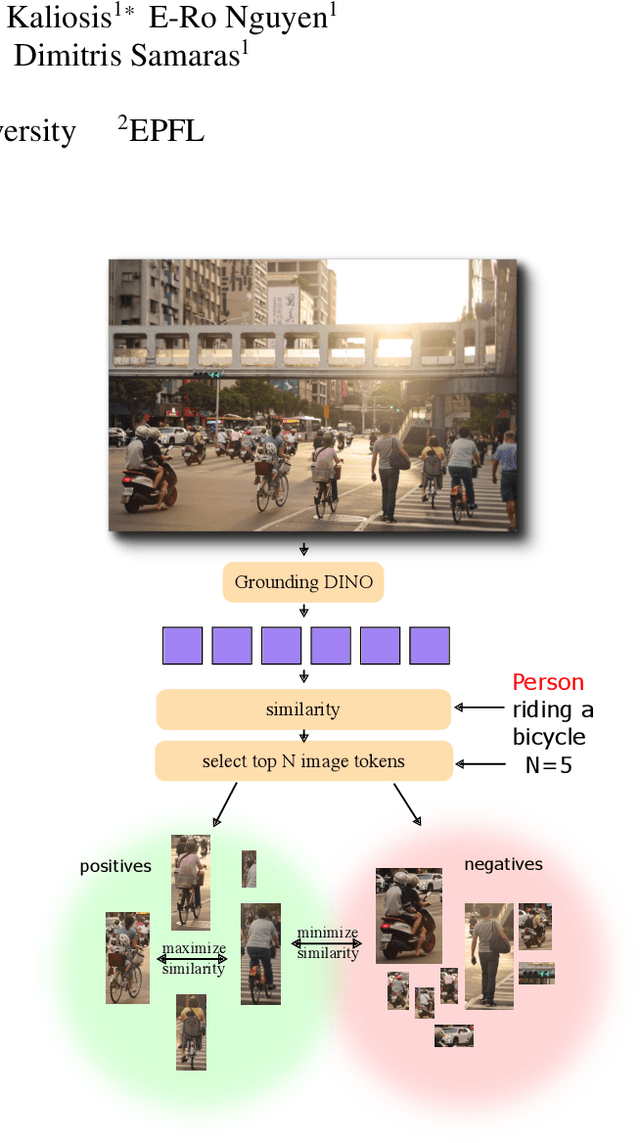
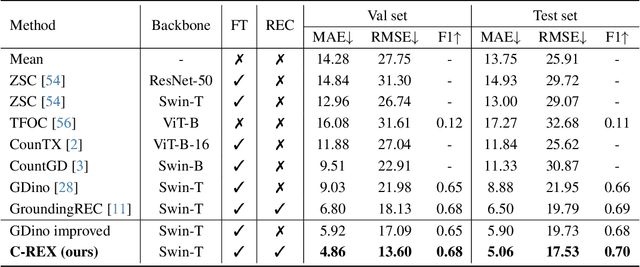

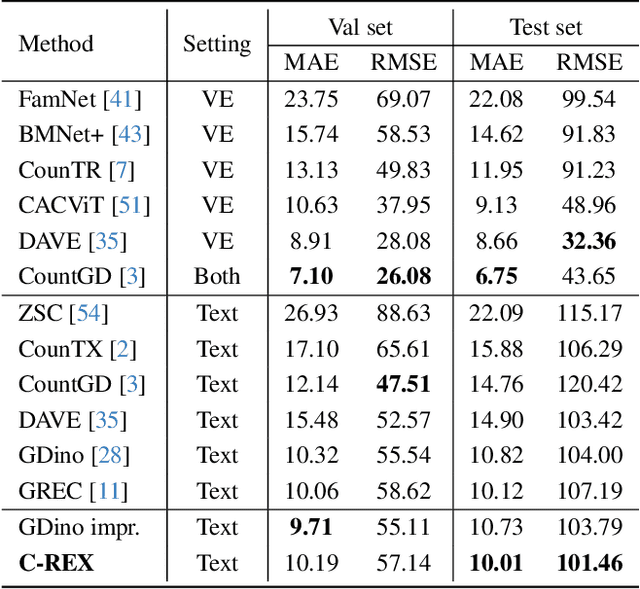
Object counting has progressed from class-specific models, which count only known categories, to class-agnostic models that generalize to unseen categories. The next challenge is Referring Expression Counting (REC), where the goal is to count objects based on fine-grained attributes and contextual differences. Existing methods struggle with distinguishing visually similar objects that belong to the same category but correspond to different referring expressions. To address this, we propose C-REX, a novel contrastive learning framework, based on supervised contrastive learning, designed to enhance discriminative representation learning. Unlike prior works, C-REX operates entirely within the image space, avoiding the misalignment issues of image-text contrastive learning, thus providing a more stable contrastive signal. It also guarantees a significantly larger pool of negative samples, leading to improved robustness in the learned representations. Moreover, we showcase that our framework is versatile and generic enough to be applied to other similar tasks like class-agnostic counting. To support our approach, we analyze the key components of sota detection-based models and identify that detecting object centroids instead of bounding boxes is the key common factor behind their success in counting tasks. We use this insight to design a simple yet effective detection-based baseline to build upon. Our experiments show that C-REX achieves state-of-the-art results in REC, outperforming previous methods by more than 22\% in MAE and more than 10\% in RMSE, while also demonstrating strong performance in class-agnostic counting. Code is available at https://github.com/cvlab-stonybrook/c-rex.
Instance-Aware Generalized Referring Expression Segmentation
Nov 22, 2024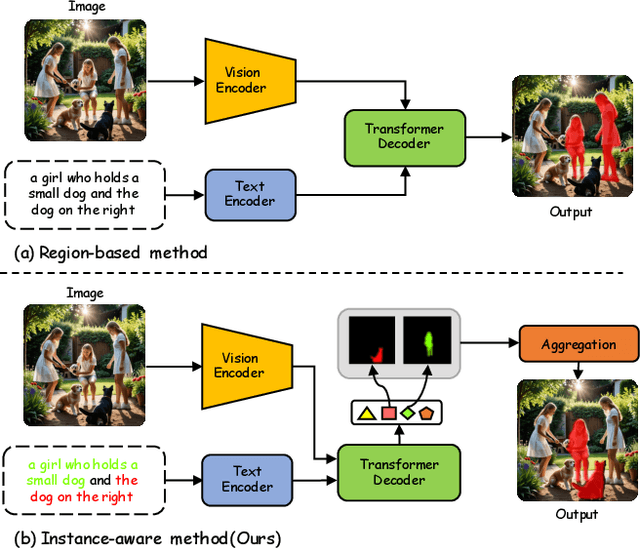
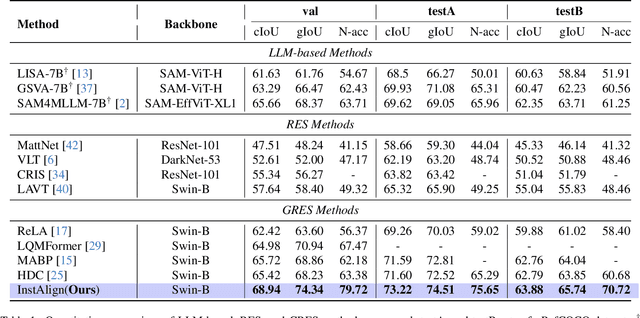
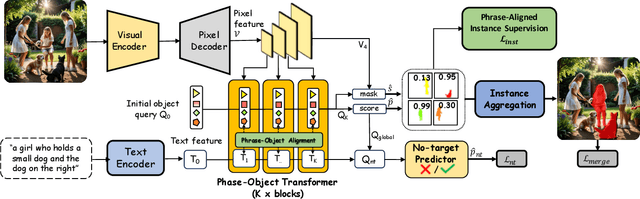
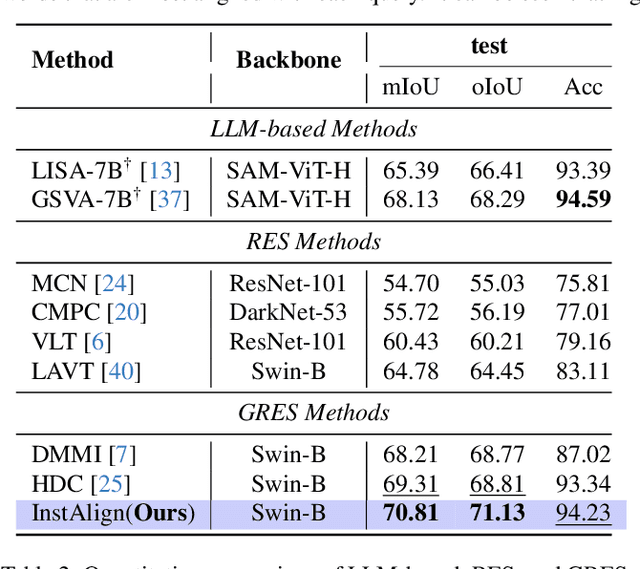
Recent works on Generalized Referring Expression Segmentation (GRES) struggle with handling complex expressions referring to multiple distinct objects. This is because these methods typically employ an end-to-end foreground-background segmentation and lack a mechanism to explicitly differentiate and associate different object instances to the text query. To this end, we propose InstAlign, a method that incorporates object-level reasoning into the segmentation process. Our model leverages both text and image inputs to extract a set of object-level tokens that capture both the semantic information in the input prompt and the objects within the image. By modeling the text-object alignment via instance-level supervision, each token uniquely represents an object segment in the image, while also aligning with relevant semantic information from the text. Extensive experiments on the gRefCOCO and Ref-ZOM benchmarks demonstrate that our method significantly advances state-of-the-art performance, setting a new standard for precise and flexible GRES.
Improving Referring Image Segmentation using Vision-Aware Text Features
Apr 12, 2024Referring image segmentation is a challenging task that involves generating pixel-wise segmentation masks based on natural language descriptions. Existing methods have relied mostly on visual features to generate the segmentation masks while treating text features as supporting components. This over-reliance on visual features can lead to suboptimal results, especially in complex scenarios where text prompts are ambiguous or context-dependent. To overcome these challenges, we present a novel framework VATEX to improve referring image segmentation by enhancing object and context understanding with Vision-Aware Text Feature. Our method involves using CLIP to derive a CLIP Prior that integrates an object-centric visual heatmap with text description, which can be used as the initial query in DETR-based architecture for the segmentation task. Furthermore, by observing that there are multiple ways to describe an instance in an image, we enforce feature similarity between text variations referring to the same visual input by two components: a novel Contextual Multimodal Decoder that turns text embeddings into vision-aware text features, and a Meaning Consistency Constraint to ensure further the coherent and consistent interpretation of language expressions with the context understanding obtained from the image. Our method achieves a significant performance improvement on three benchmark datasets RefCOCO, RefCOCO+ and G-Ref. Code is available at: https://nero1342.github.io/VATEX\_RIS.
TextANIMAR: Text-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023



3D object retrieval is an important yet challenging task, which has drawn more and more attention in recent years. While existing approaches have made strides in addressing this issue, they are often limited to restricted settings such as image and sketch queries, which are often unfriendly interactions for common users. In order to overcome these limitations, this paper presents a novel SHREC challenge track focusing on text-based fine-grained retrieval of 3D animal models. Unlike previous SHREC challenge tracks, the proposed task is considerably more challenging, requiring participants to develop innovative approaches to tackle the problem of text-based retrieval. Despite the increased difficulty, we believe that this task has the potential to drive useful applications in practice and facilitate more intuitive interactions with 3D objects. Five groups participated in our competition, submitting a total of 114 runs. While the results obtained in our competition are satisfactory, we note that the challenges presented by this task are far from being fully solved. As such, we provide insights into potential areas for future research and improvements. We believe that we can help push the boundaries of 3D object retrieval and facilitate more user-friendly interactions via vision-language technologies.