 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow You Move Tells What You'll Do: Trajectory-Conditioned Egocentric Prediction
May 19, 2026Predicting how a person's first-person view will evolve (what action will follow, what plan completes a task, whether an in-progress shot will score) is fundamentally under-specified: the same context admits many plausible futures, and a model trained to minimize prediction error is forced to hedge or average across them, getting it wrong either way. Two findings shape our approach. First, the future camera trajectory, the path the head carves through space, lets the model commit to one of those futures: it carries the operator's intent in a form fine enough to determine how an action will unfold, substantially outperforming language as a conditioning signal. Second, this same intent makes the trajectory itself partially predictable from the context at hand, enough that trajectory need not be observed at test time to recover most of the gain. We instantiate these findings as TrajPilot, a model that predicts candidate future trajectories from egocentric context and uses them to pilot action prediction in an action-aligned embedding space where language shapes the structure but is never used as a conditioning input. TrajPilot beats VLM and structured-planner baselines on procedural planning across Ego-Exo4D atomic, Ego-Exo4D Keystep, Ego4D GoalStep, and EgoPER, with the trajectory advantage widening with horizon (exactly where prior planners collapse) and holding under RGB-only camera-pose estimation. With the goal masked at inference, the same model performs goal-free anticipation, beating VLM baselines on Ego-Exo4D atomic and extending to EPIC-Kitchens-100 and basketball shot-outcome prediction.
Toward an Artificial General Teacher: Procedural Geometry Data Generation and Visual Grounding with Vision-Language Models
Apr 03, 2026We study visual explanation in geometry education as a Referring Image Segmentation (RIS) problem: given a diagram and a natural language description, the task is to produce a pixel-level mask for the referred geometric element. However, existing RIS models trained on natural image benchmarks such as RefCOCO fail catastrophically on geometric diagrams due to the fundamental domain shift between photographic scenes and abstract, textureless schematics. To address the absence of suitable training data, we present a fully automated procedural data engine that generates over 200,000 synthetic geometry diagrams with pixel-perfect segmentation masks and linguistically diverse referring expressions, requiring zero manual annotation. We further propose domain-specific fine-tuning of vision-language models (VLMs), demonstrating that a fine-tuned Florence-2 achieves 49% IoU and 85% Buffered IoU (BIoU), compared to <1% IoU in zero-shot settings. We introduce Buffered IoU, a geometry-aware evaluation metric that accounts for thin-structure localization, and show that it better reflects true segmentation quality than standard IoU. Our results establish a foundation for building Artificial General Teachers (AGTs) capable of providing visually grounded, step-by-step explanations of geometry problems.
Improving Referring Image Segmentation using Vision-Aware Text Features
Apr 12, 2024


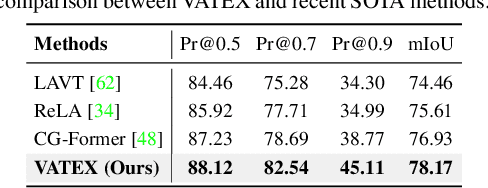
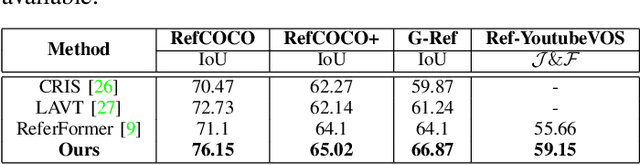
Referring image segmentation is a challenging task that involves generating pixel-wise segmentation masks based on natural language descriptions. Existing methods have relied mostly on visual features to generate the segmentation masks while treating text features as supporting components. This over-reliance on visual features can lead to suboptimal results, especially in complex scenarios where text prompts are ambiguous or context-dependent. To overcome these challenges, we present a novel framework VATEX to improve referring image segmentation by enhancing object and context understanding with Vision-Aware Text Feature. Our method involves using CLIP to derive a CLIP Prior that integrates an object-centric visual heatmap with text description, which can be used as the initial query in DETR-based architecture for the segmentation task. Furthermore, by observing that there are multiple ways to describe an instance in an image, we enforce feature similarity between text variations referring to the same visual input by two components: a novel Contextual Multimodal Decoder that turns text embeddings into vision-aware text features, and a Meaning Consistency Constraint to ensure further the coherent and consistent interpretation of language expressions with the context understanding obtained from the image. Our method achieves a significant performance improvement on three benchmark datasets RefCOCO, RefCOCO+ and G-Ref. Code is available at: https://nero1342.github.io/VATEX\_RIS.
The 2nd Workshop on Maritime Computer Vision 2024
Nov 23, 2023



The 2nd Workshop on Maritime Computer Vision (MaCVi) 2024 addresses maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicles (USV). Three challenges categories are considered: (i) UAV-based Maritime Object Tracking with Re-identification, (ii) USV-based Maritime Obstacle Segmentation and Detection, (iii) USV-based Maritime Boat Tracking. The USV-based Maritime Obstacle Segmentation and Detection features three sub-challenges, including a new embedded challenge addressing efficicent inference on real-world embedded devices. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 195 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi24.
MarineVRS: Marine Video Retrieval System with Explainability via Semantic Understanding
Jun 07, 2023
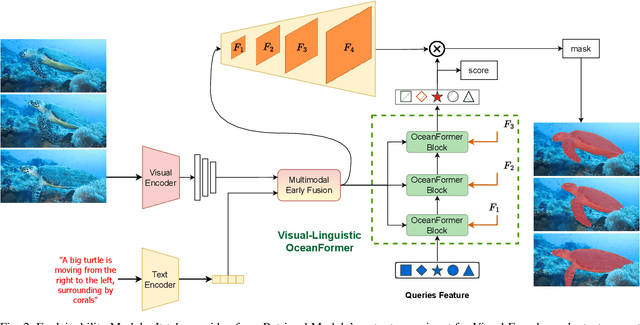

Building a video retrieval system that is robust and reliable, especially for the marine environment, is a challenging task due to several factors such as dealing with massive amounts of dense and repetitive data, occlusion, blurriness, low lighting conditions, and abstract queries. To address these challenges, we present MarineVRS, a novel and flexible video retrieval system designed explicitly for the marine domain. MarineVRS integrates state-of-the-art methods for visual and linguistic object representation to enable efficient and accurate search and analysis of vast volumes of underwater video data. In addition, unlike the conventional video retrieval system, which only permits users to index a collection of images or videos and search using a free-form natural language sentence, our retrieval system includes an additional Explainability module that outputs the segmentation masks of the objects that the input query referred to. This feature allows users to identify and isolate specific objects in the video footage, leading to more detailed analysis and understanding of their behavior and movements. Finally, with its adaptability, explainability, accuracy, and scalability, MarineVRS is a powerful tool for marine researchers and scientists to efficiently and accurately process vast amounts of data and gain deeper insights into the behavior and movements of marine species.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

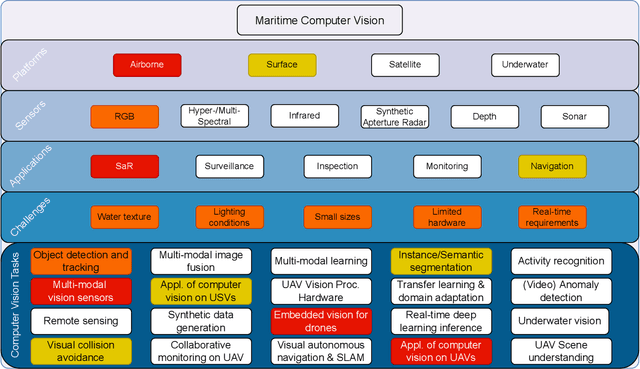
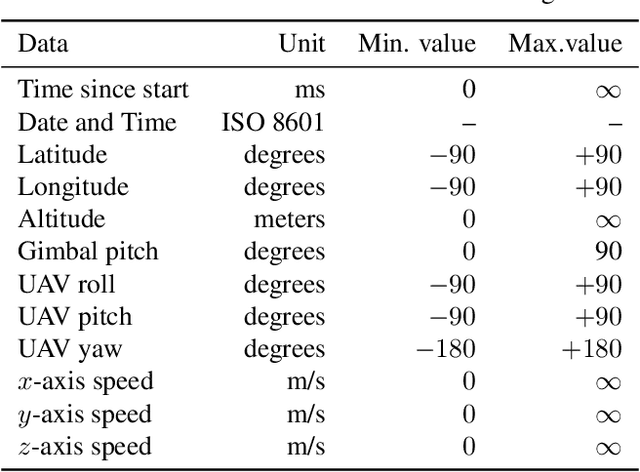
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
SegTransVAE: Hybrid CNN -- Transformer with Regularization for medical image segmentation
Jan 26, 2022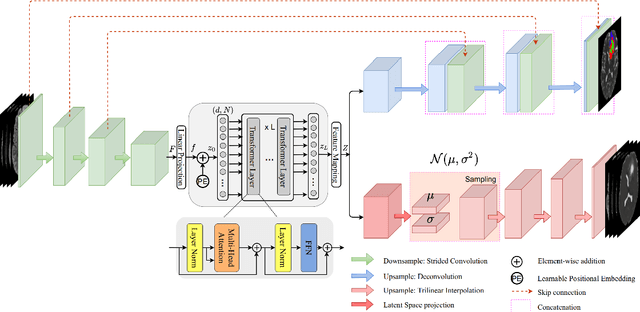
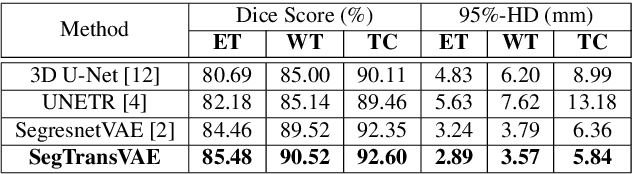
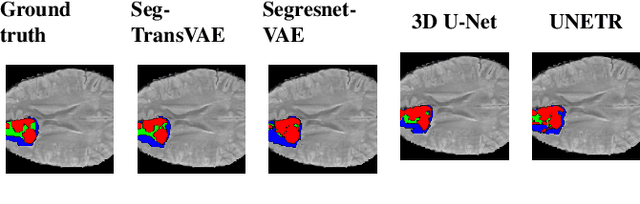
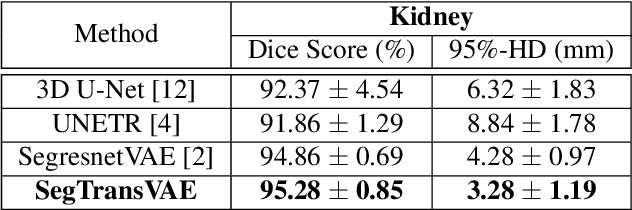
Current research on deep learning for medical image segmentation exposes their limitations in learning either global semantic information or local contextual information. To tackle these issues, a novel network named SegTransVAE is proposed in this paper. SegTransVAE is built upon encoder-decoder architecture, exploiting transformer with the variational autoencoder (VAE) branch to the network to reconstruct the input images jointly with segmentation. To the best of our knowledge, this is the first method combining the success of CNN, transformer, and VAE. Evaluation on various recently introduced datasets shows that SegTransVAE outperforms previous methods in Dice Score and $95\%$-Haudorff Distance while having comparable inference time to a simple CNN-based architecture network. The source code is available at: https://github.com/itruonghai/SegTransVAE.