 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolySAE: Modeling Feature Interactions in Sparse Autoencoders via Polynomial Decoding
Feb 01, 2026Sparse autoencoders (SAEs) have emerged as a promising method for interpreting neural network representations by decomposing activations into sparse combinations of dictionary atoms. However, SAEs assume that features combine additively through linear reconstruction, an assumption that cannot capture compositional structure: linear models cannot distinguish whether "Starbucks" arises from the composition of "star" and "coffee" features or merely their co-occurrence. This forces SAEs to allocate monolithic features for compound concepts rather than decomposing them into interpretable constituents. We introduce PolySAE, which extends the SAE decoder with higher-order terms to model feature interactions while preserving the linear encoder essential for interpretability. Through low-rank tensor factorization on a shared projection subspace, PolySAE captures pairwise and triple feature interactions with small parameter overhead (3% on GPT2). Across four language models and three SAE variants, PolySAE achieves an average improvement of approximately 8% in probing F1 while maintaining comparable reconstruction error, and produces 2-10$\times$ larger Wasserstein distances between class-conditional feature distributions. Critically, learned interaction weights exhibit negligible correlation with co-occurrence frequency ($r = 0.06$ vs. $r = 0.82$ for SAE feature covariance), suggesting that polynomial terms capture compositional structure, such as morphological binding and phrasal composition, largely independent of surface statistics.
A Principled Framework for Multi-View Contrastive Learning
Jul 09, 2025Contrastive Learning (CL), a leading paradigm in Self-Supervised Learning (SSL), typically relies on pairs of data views generated through augmentation. While multiple augmentations per instance (more than two) improve generalization in supervised learning, current CL methods handle additional views suboptimally by simply aggregating different pairwise objectives. This approach suffers from four critical limitations: (L1) it utilizes multiple optimization terms per data point resulting to conflicting objectives, (L2) it fails to model all interactions across views and data points, (L3) it inherits fundamental limitations (e.g. alignment-uniformity coupling) from pairwise CL losses, and (L4) it prevents fully realizing the benefits of increased view multiplicity observed in supervised settings. We address these limitations through two novel loss functions: MV-InfoNCE, which extends InfoNCE to incorporate all possible view interactions simultaneously in one term per data point, and MV-DHEL, which decouples alignment from uniformity across views while scaling interaction complexity with view multiplicity. Both approaches are theoretically grounded - we prove they asymptotically optimize for alignment of all views and uniformity, providing principled extensions to multi-view contrastive learning. Our empirical results on ImageNet1K and three other datasets demonstrate that our methods consistently outperform existing multi-view approaches and effectively scale with increasing view multiplicity. We also apply our objectives to multimodal data and show that, in contrast to other contrastive objectives, they can scale beyond just two modalities. Most significantly, ablation studies reveal that MV-DHEL with five or more views effectively mitigates dimensionality collapse by fully utilizing the embedding space, thereby delivering multi-view benefits observed in supervised learning.
Bridging Mini-Batch and Asymptotic Analysis in Contrastive Learning: From InfoNCE to Kernel-Based Losses
May 28, 2024



What do different contrastive learning (CL) losses actually optimize for? Although multiple CL methods have demonstrated remarkable representation learning capabilities, the differences in their inner workings remain largely opaque. In this work, we analyse several CL families and prove that, under certain conditions, they admit the same minimisers when optimizing either their batch-level objectives or their expectations asymptotically. In both cases, an intimate connection with the hyperspherical energy minimisation (HEM) problem resurfaces. Drawing inspiration from this, we introduce a novel CL objective, coined Decoupled Hyperspherical Energy Loss (DHEL). DHEL simplifies the problem by decoupling the target hyperspherical energy from the alignment of positive examples while preserving the same theoretical guarantees. Going one step further, we show the same results hold for another relevant CL family, namely kernel contrastive learning (KCL), with the additional advantage of the expected loss being independent of batch size, thus identifying the minimisers in the non-asymptotic regime. Empirical results demonstrate improved downstream performance and robustness across combinations of different batch sizes and hyperparameters and reduced dimensionality collapse, on several computer vision datasets.
A Dataset for Speech Emotion Recognition in Greek Theatrical Plays
Mar 27, 2022
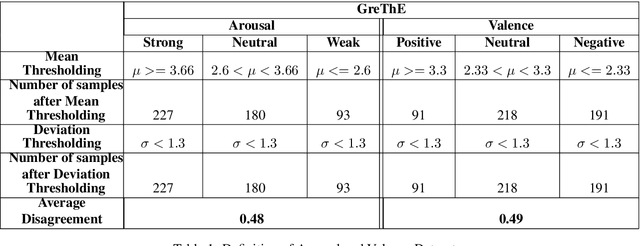
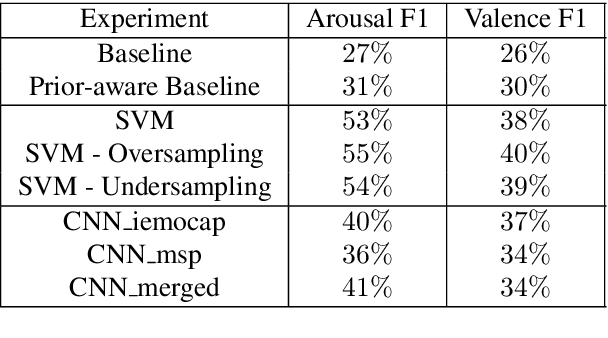
Machine learning methodologies can be adopted in cultural applications and propose new ways to distribute or even present the cultural content to the public. For instance, speech analytics can be adopted to automatically generate subtitles in theatrical plays, in order to (among other purposes) help people with hearing loss. Apart from a typical speech-to-text transcription with Automatic Speech Recognition (ASR), Speech Emotion Recognition (SER) can be used to automatically predict the underlying emotional content of speech dialogues in theatrical plays, and thus to provide a deeper understanding how the actors utter their lines. However, real-world datasets from theatrical plays are not available in the literature. In this work we present GreThE, the Greek Theatrical Emotion dataset, a new publicly available data collection for speech emotion recognition in Greek theatrical plays. The dataset contains utterances from various actors and plays, along with respective valence and arousal annotations. Towards this end, multiple annotators have been asked to provide their input for each speech recording and inter-annotator agreement is taken into account in the final ground truth generation. In addition, we discuss the results of some indicative experiments that have been conducted with machine and deep learning frameworks, using the dataset, along with some widely used databases in the field of speech emotion recognition.
Unsupervised Multimodal Language Representations using Convolutional Autoencoders
Oct 06, 2021
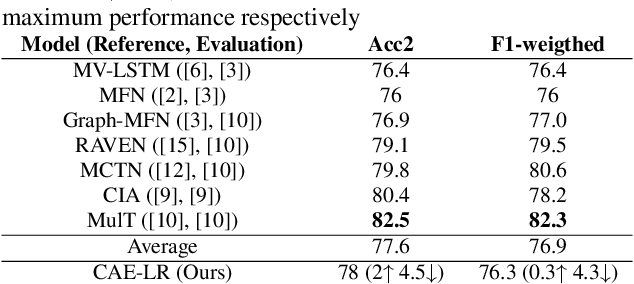
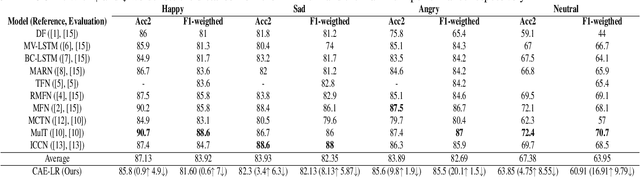
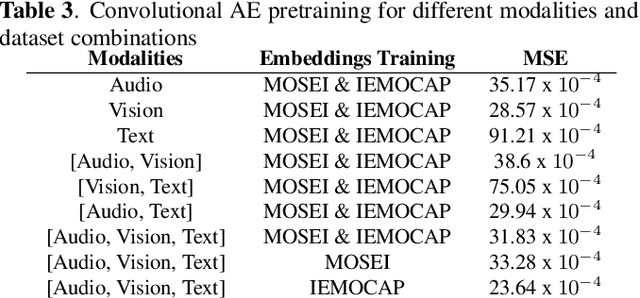
Multimodal Language Analysis is a demanding area of research, since it is associated with two requirements: combining different modalities and capturing temporal information. During the last years, several works have been proposed in the area, mostly centered around supervised learning in downstream tasks. In this paper we propose extracting unsupervised Multimodal Language representations that are universal and can be applied to different tasks. Towards this end, we map the word-level aligned multimodal sequences to 2-D matrices and then use Convolutional Autoencoders to learn embeddings by combining multiple datasets. Extensive experimentation on Sentiment Analysis (MOSEI) and Emotion Recognition (IEMOCAP) indicate that the learned representations can achieve near-state-of-the-art performance with just the use of a Logistic Regression algorithm for downstream classification. It is also shown that our method is extremely lightweight and can be easily generalized to other tasks and unseen data with small performance drop and almost the same number of parameters. The proposed multimodal representation models are open-sourced and will help grow the applicability of Multimodal Language.