 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Sep 10, 2020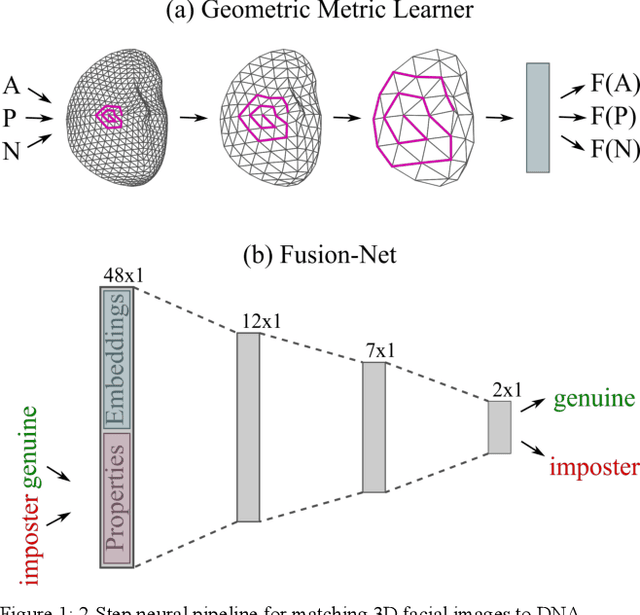
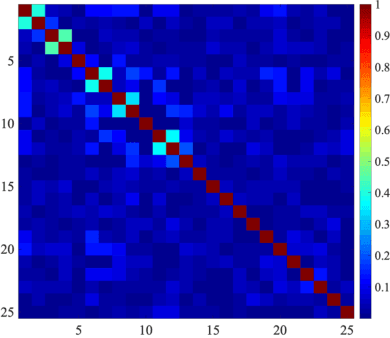
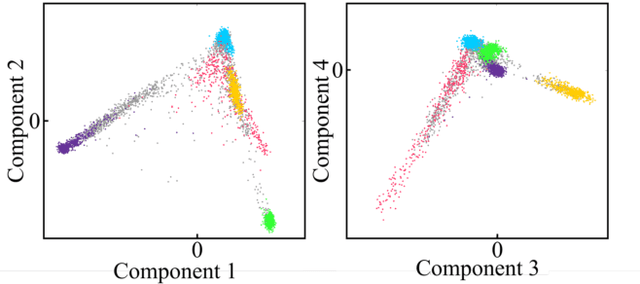

Face recognition is a widely accepted biometric verification tool, as the face contains a lot of information about the identity of a person. In this study, a 2-step neural-based pipeline is presented for matching 3D facial shape to multiple DNA-related properties (sex, age, BMI and genomic background). The first step consists of a triplet loss-based metric learner that compresses facial shape into a lower dimensional embedding while preserving information about the property of interest. Most studies in the field of metric learning have only focused on Euclidean data. In this work, geometric deep learning is employed to learn directly from 3D facial meshes. To this end, spiral convolutions are used along with a novel mesh-sampling scheme that retains uniformly sampled 3D points at different levels of resolution. The second step is a multi-biometric fusion by a fully connected neural network. The network takes an ensemble of embeddings and property labels as input and returns genuine and imposter scores. Since embeddings are accepted as an input, there is no need to train classifiers for the different properties and available data can be used more efficiently. Results obtained by a 10-fold cross-validation for biometric verification show that combining multiple properties leads to stronger biometric systems. Furthermore, the proposed neural-based pipeline outperforms a linear baseline, which consists of principal component analysis, followed by classification with linear support vector machines and a Naive Bayes-based score-fuser.
Neural 3D Morphable Models: Spiral Convolutional Networks for 3D Shape Representation Learning and Generation
May 09, 2019
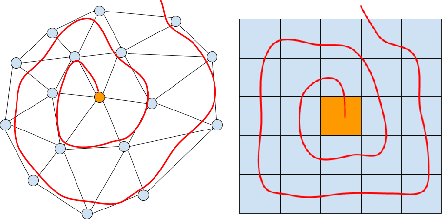
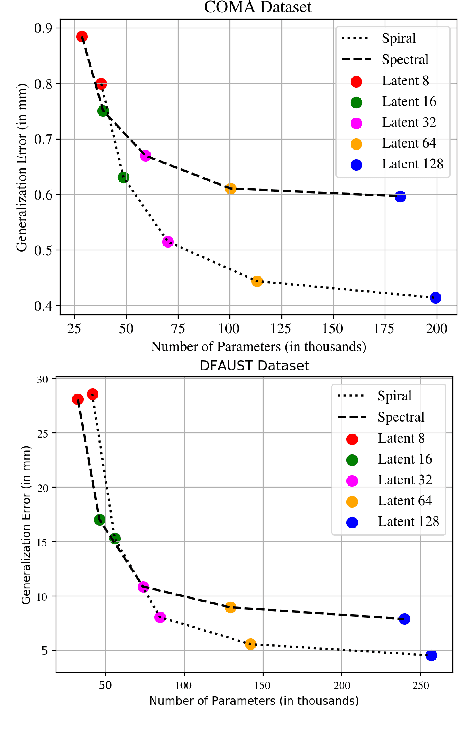
Generative models for 3D geometric data arise in many important applications in 3D computer vision and graphics. In this paper, we focus on 3D deformable shapes that share a common topological structure, such as human faces and bodies. Morphable Models were among the first attempts to create compact representations for such shapes; despite their effectiveness and simplicity, such models have limited representation power due to their linear formulation. Recently, non-linear learnable methods have been proposed, although most of them resort to intermediate representations, such as 3D grids of voxels or 2D views. In this paper, we introduce a convolutional mesh autoencoder and a GAN architecture based on the spiral convolutional operator, acting directly on the mesh and leveraging its underlying geometric structure. We provide an analysis of our convolution operator and demonstrate state-of-the-art results on 3D shape datasets compared to the linear Morphable Model and the recently proposed COMA model.