 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural 3D Morphable Models: Spiral Convolutional Networks for 3D Shape Representation Learning and Generation
Paper and Code

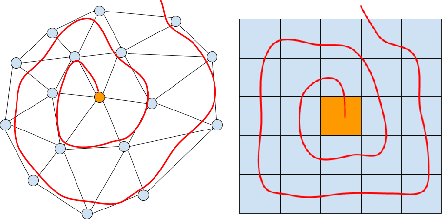
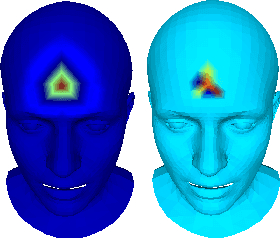
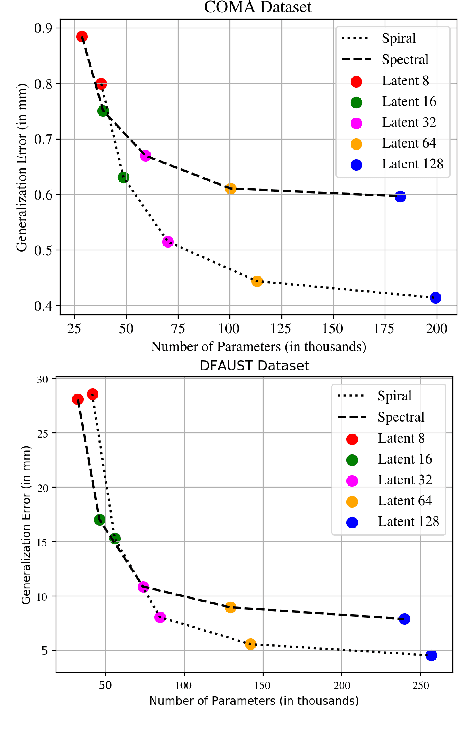
Generative models for 3D geometric data arise in many important applications in 3D computer vision and graphics. In this paper, we focus on 3D deformable shapes that share a common topological structure, such as human faces and bodies. Morphable Models were among the first attempts to create compact representations for such shapes; despite their effectiveness and simplicity, such models have limited representation power due to their linear formulation. Recently, non-linear learnable methods have been proposed, although most of them resort to intermediate representations, such as 3D grids of voxels or 2D views. In this paper, we introduce a convolutional mesh autoencoder and a GAN architecture based on the spiral convolutional operator, acting directly on the mesh and leveraging its underlying geometric structure. We provide an analysis of our convolution operator and demonstrate state-of-the-art results on 3D shape datasets compared to the linear Morphable Model and the recently proposed COMA model.