 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape My Face: Registering 3D Face Scans by Surface-to-Surface Translation
Dec 16, 2020
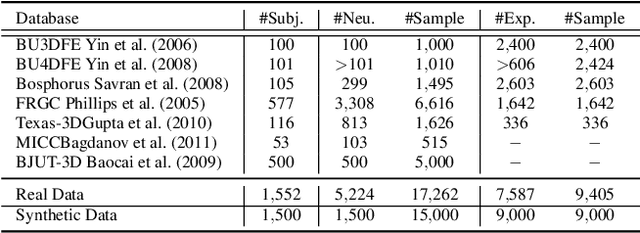

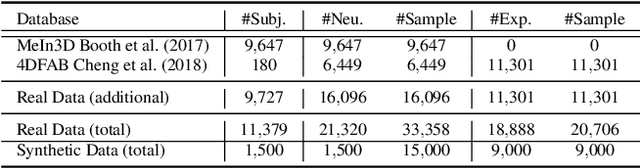
Existing surface registration methods focus on fitting in-sample data with little to no generalization ability and require both heavy pre-processing and careful hand-tuning. In this paper, we cast the registration task as a surface-to-surface translation problem, and design a model to reliably capture the latent geometric information directly from raw 3D face scans. We introduce Shape-My-Face (SMF), a powerful encoder-decoder architecture based on an improved point cloud encoder, a novel visual attention mechanism, graph convolutional decoders with skip connections, and a specialized mouth model that we smoothly integrate with the mesh convolutions. Compared to the previous state-of-the-art learning algorithms for non-rigid registration of face scans, SMF only requires the raw data to be rigidly aligned (with scaling) with a pre-defined face template. Additionally, our model provides topologically-sound meshes with minimal supervision, offers faster training time, has orders of magnitude fewer trainable parameters, is more robust to noise, and can generalize to previously unseen datasets. We extensively evaluate the quality of our registrations on diverse data. We demonstrate the robustness and generalizability of our model with in-the-wild face scans across different modalities, sensor types, and resolutions. Finally, we show that, by learning to register scans, SMF produces a hybrid linear and non-linear morphable model that can be used for generation, shape morphing, and expression transfer through manipulation of the latent space, including in-the-wild. We train SMF on a dataset of human faces comprising 9 large-scale databases on commodity hardware.
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Sep 10, 2020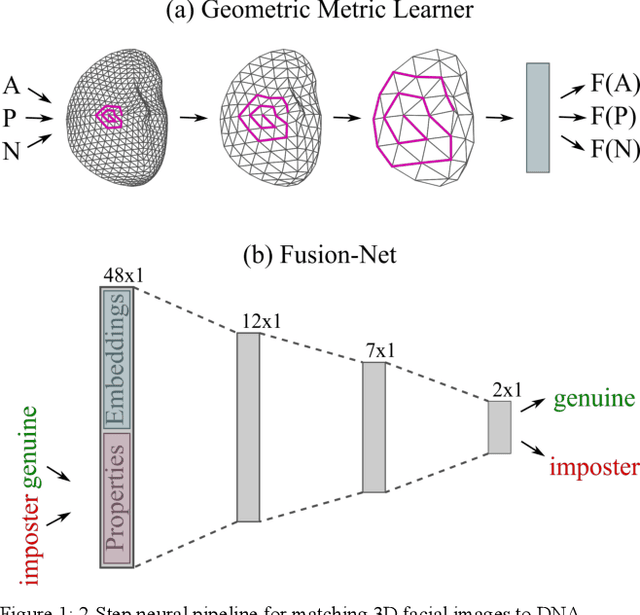
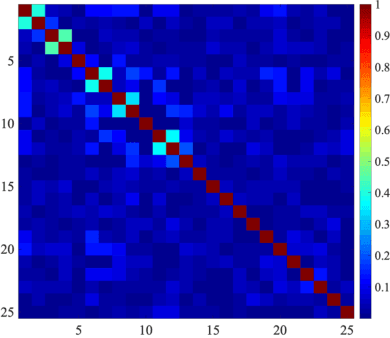
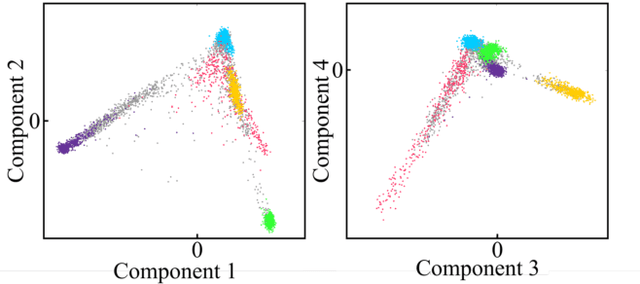

Face recognition is a widely accepted biometric verification tool, as the face contains a lot of information about the identity of a person. In this study, a 2-step neural-based pipeline is presented for matching 3D facial shape to multiple DNA-related properties (sex, age, BMI and genomic background). The first step consists of a triplet loss-based metric learner that compresses facial shape into a lower dimensional embedding while preserving information about the property of interest. Most studies in the field of metric learning have only focused on Euclidean data. In this work, geometric deep learning is employed to learn directly from 3D facial meshes. To this end, spiral convolutions are used along with a novel mesh-sampling scheme that retains uniformly sampled 3D points at different levels of resolution. The second step is a multi-biometric fusion by a fully connected neural network. The network takes an ensemble of embeddings and property labels as input and returns genuine and imposter scores. Since embeddings are accepted as an input, there is no need to train classifiers for the different properties and available data can be used more efficiently. Results obtained by a 10-fold cross-validation for biometric verification show that combining multiple properties leads to stronger biometric systems. Furthermore, the proposed neural-based pipeline outperforms a linear baseline, which consists of principal component analysis, followed by classification with linear support vector machines and a Naive Bayes-based score-fuser.
Geometrically Principled Connections in Graph Neural Networks
Apr 06, 2020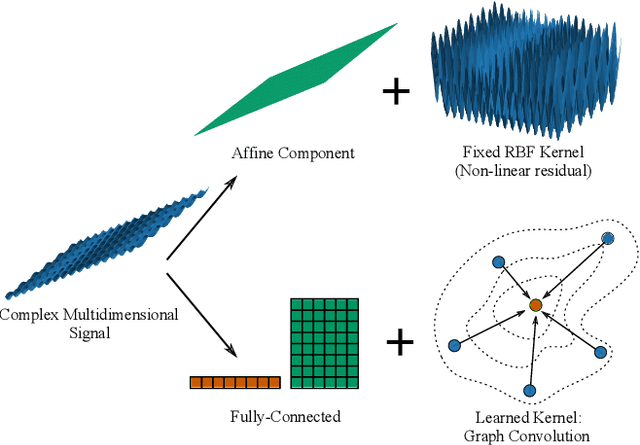
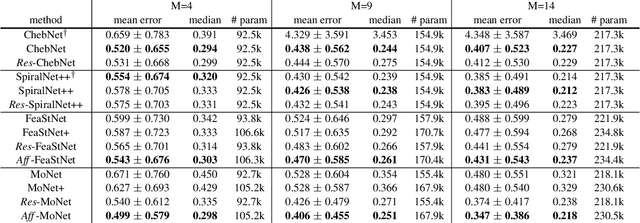
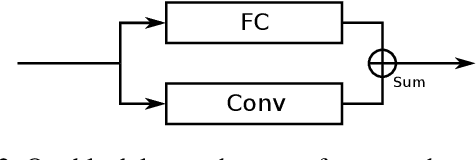
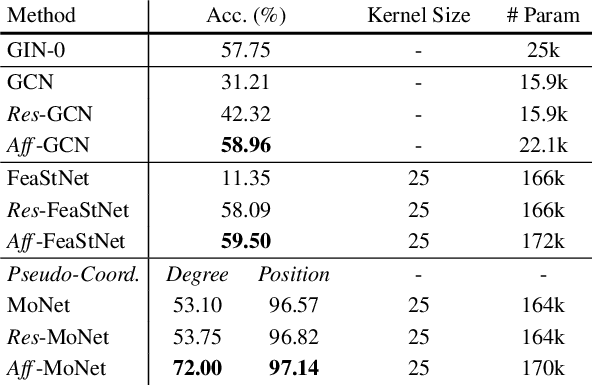
Graph convolution operators bring the advantages of deep learning to a variety of graph and mesh processing tasks previously deemed out of reach. With their continued success comes the desire to design more powerful architectures, often by adapting existing deep learning techniques to non-Euclidean data. In this paper, we argue geometry should remain the primary driving force behind innovation in the emerging field of geometric deep learning. We relate graph neural networks to widely successful computer graphics and data approximation models: radial basis functions (RBFs). We conjecture that, like RBFs, graph convolution layers would benefit from the addition of simple functions to the powerful convolution kernels. We introduce affine skip connections, a novel building block formed by combining a fully connected layer with any graph convolution operator. We experimentally demonstrate the effectiveness of our technique and show the improved performance is the consequence of more than the increased number of parameters. Operators equipped with the affine skip connection markedly outperform their base performance on every task we evaluated, i.e., shape reconstruction, dense shape correspondence, and graph classification. We hope our simple and effective approach will serve as a solid baseline and help ease future research in graph neural networks.
Graph Attentional Autoencoder for Anticancer Hyperfood Prediction
Jan 16, 2020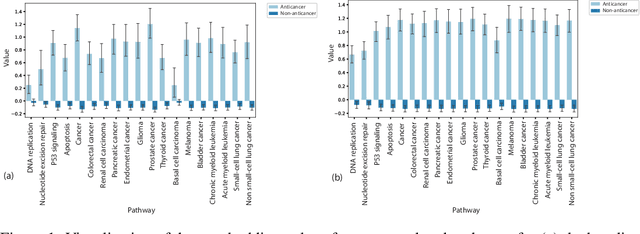
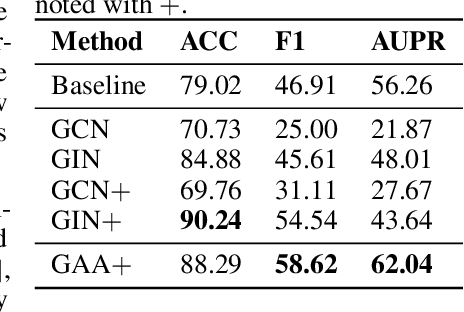
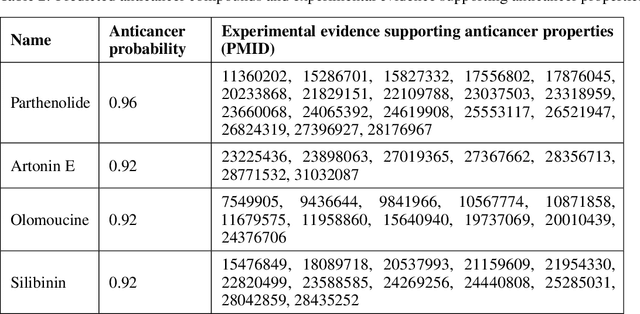
Recent research efforts have shown the possibility to discover anticancer drug-like molecules in food from their effect on protein-protein interaction networks, opening a potential pathway to disease-beating diet design. We formulate this task as a graph classification problem on which graph neural networks (GNNs) have achieved state-of-the-art results. However, GNNs are difficult to train on sparse low-dimensional features according to our empirical evidence. Here, we present graph augmented features, integrating graph structural information and raw node attributes with varying ratios, to ease the training of networks. We further introduce a novel neural network architecture on graphs, the Graph Attentional Autoencoder (GAA) to predict food compounds with anticancer properties based on perturbed protein networks. We demonstrate that the method outperforms the baseline approach and state-of-the-art graph classification models in this task.
SpiralNet++: A Fast and Highly Efficient Mesh Convolution Operator
Nov 13, 2019


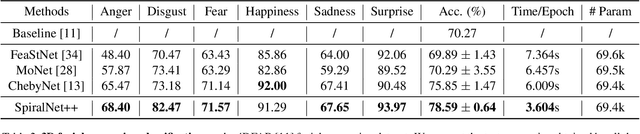
Intrinsic graph convolution operators with differentiable kernel functions play a crucial role in analyzing 3D shape meshes. In this paper, we present a fast and efficient intrinsic mesh convolution operator that does not rely on the intricate design of kernel function. We explicitly formulate the order of aggregating neighboring vertices, instead of learning weights between nodes, and then a fully connected layer follows to fuse local geometric structure information with vertex features. We provide extensive evidence showing that models based on this convolution operator are easier to train, and can efficiently learn invariant shape features. Specifically, we evaluate our method on three different types of tasks of dense shape correspondence, 3D facial expression classification, and 3D shape reconstruction, and show that it significantly outperforms state-of-the-art approaches while being significantly faster, without relying on shape descriptors. Our source code is available on GitHub.