 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2021 BEETL Competition: Advancing Transfer Learning for Subject Independence & Heterogenous EEG Data Sets
Feb 14, 2022
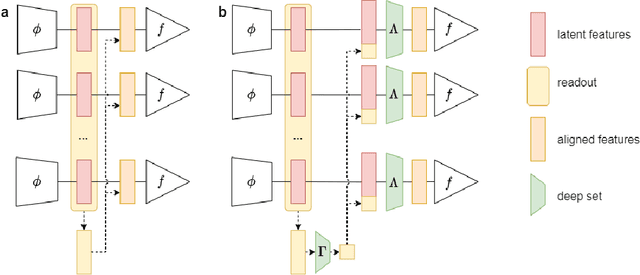
Transfer learning and meta-learning offer some of the most promising avenues to unlock the scalability of healthcare and consumer technologies driven by biosignal data. This is because current methods cannot generalise well across human subjects' data and handle learning from different heterogeneously collected data sets, thus limiting the scale of training data. On the other side, developments in transfer learning would benefit significantly from a real-world benchmark with immediate practical application. Therefore, we pick electroencephalography (EEG) as an exemplar for what makes biosignal machine learning hard. We design two transfer learning challenges around diagnostics and Brain-Computer-Interfacing (BCI), that have to be solved in the face of low signal-to-noise ratios, major variability among subjects, differences in the data recording sessions and techniques, and even between the specific BCI tasks recorded in the dataset. Task 1 is centred on the field of medical diagnostics, addressing automatic sleep stage annotation across subjects. Task 2 is centred on Brain-Computer Interfacing (BCI), addressing motor imagery decoding across both subjects and data sets. The BEETL competition with its over 30 competing teams and its 3 winning entries brought attention to the potential of deep transfer learning and combinations of set theory and conventional machine learning techniques to overcome the challenges. The results set a new state-of-the-art for the real-world BEETL benchmark.
Team Cogitat at NeurIPS 2021: Benchmarks for EEG Transfer Learning Competition
Feb 01, 2022

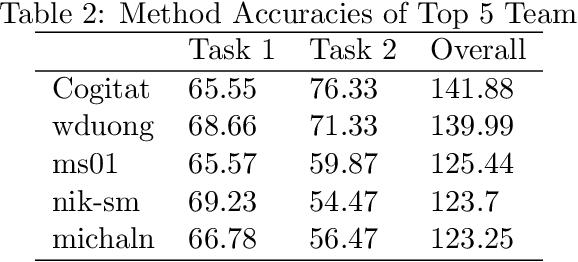
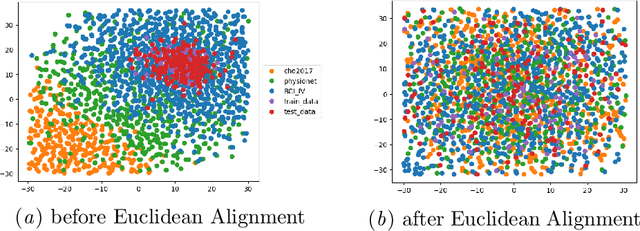
Building subject-independent deep learning models for EEG decoding faces the challenge of strong covariate-shift across different datasets, subjects and recording sessions. Our approach to address this difficulty is to explicitly align feature distributions at various layers of the deep learning model, using both simple statistical techniques as well as trainable methods with more representational capacity. This follows in a similar vein as covariance-based alignment methods, often used in a Riemannian manifold context. The methodology proposed herein won first place in the 2021 Benchmarks in EEG Transfer Learning (BEETL) competition, hosted at the NeurIPS conference. The first task of the competition consisted of sleep stage classification, which required the transfer of models trained on younger subjects to perform inference on multiple subjects of older age groups without personalized calibration data, requiring subject-independent models. The second task required to transfer models trained on the subjects of one or more source motor imagery datasets to perform inference on two target datasets, providing a small set of personalized calibration data for multiple test subjects.
Road Extraction from Overhead Images with Graph Neural Networks
Dec 09, 2021
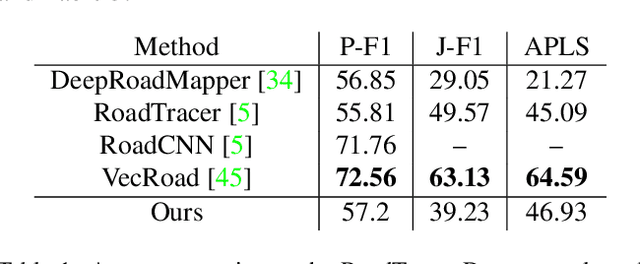
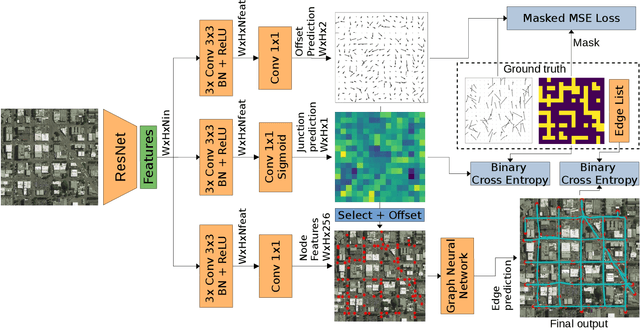

Automatic road graph extraction from aerial and satellite images is a long-standing challenge. Existing algorithms are either based on pixel-level segmentation followed by vectorization, or on iterative graph construction using next move prediction. Both of these strategies suffer from severe drawbacks, in particular high computing resources and incomplete outputs. By contrast, we propose a method that directly infers the final road graph in a single pass. The key idea consists in combining a Fully Convolutional Network in charge of locating points of interest such as intersections, dead ends and turns, and a Graph Neural Network which predicts links between these points. Such a strategy is more efficient than iterative methods and allows us to streamline the training process by removing the need for generation of starting locations while keeping the training end-to-end. We evaluate our method against existing works on the popular RoadTracer dataset and achieve competitive results. We also benchmark the speed of our method and show that it outperforms existing approaches. This opens the possibility of in-flight processing on embedded devices.
Binary Graph Neural Networks
Dec 31, 2020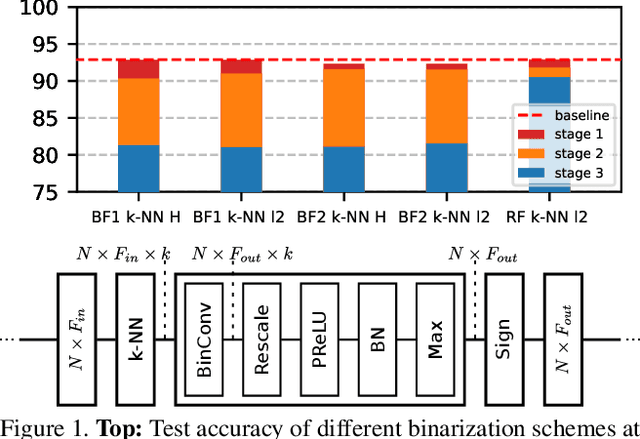
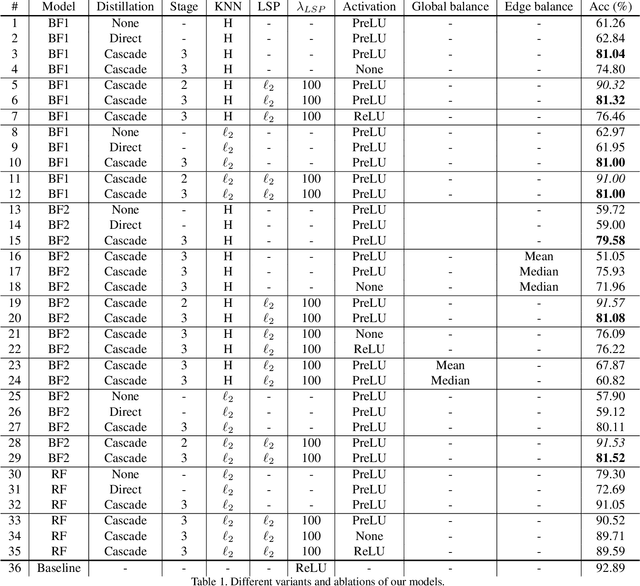
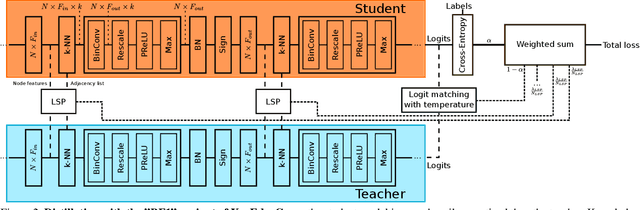
Graph Neural Networks (GNNs) have emerged as a powerful and flexible framework for representation learning on irregular data. As they generalize the operations of classical CNNs on grids to arbitrary topologies, GNNs also bring much of the implementation challenges of their Euclidean counterparts. Model size, memory footprint, and energy consumption are common concerns for many real-world applications. Network binarization allocates a single bit to network parameters and activations, thus dramatically reducing the memory requirements (up to 32x compared to single-precision floating-point parameters) and maximizing the benefits of fast SIMD instructions of modern hardware for measurable speedups. However, in spite of the large body of work on binarization for classical CNNs, this area remains largely unexplored in geometric deep learning. In this paper, we present and evaluate different strategies for the binarization of graph neural networks. We show that through careful design of the models, and control of the training process, binary graph neural networks can be trained at only a moderate cost in accuracy on challenging benchmarks. In particular, we present the first dynamic graph neural network in Hamming space, able to leverage efficient $k$-NN search on binary vectors to speed-up the construction of the dynamic graph. We further verify that the binary models offer significant savings on embedded devices.
Shape My Face: Registering 3D Face Scans by Surface-to-Surface Translation
Dec 16, 2020
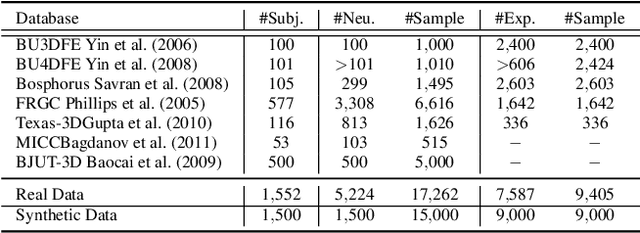

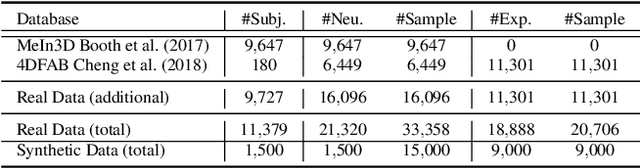
Existing surface registration methods focus on fitting in-sample data with little to no generalization ability and require both heavy pre-processing and careful hand-tuning. In this paper, we cast the registration task as a surface-to-surface translation problem, and design a model to reliably capture the latent geometric information directly from raw 3D face scans. We introduce Shape-My-Face (SMF), a powerful encoder-decoder architecture based on an improved point cloud encoder, a novel visual attention mechanism, graph convolutional decoders with skip connections, and a specialized mouth model that we smoothly integrate with the mesh convolutions. Compared to the previous state-of-the-art learning algorithms for non-rigid registration of face scans, SMF only requires the raw data to be rigidly aligned (with scaling) with a pre-defined face template. Additionally, our model provides topologically-sound meshes with minimal supervision, offers faster training time, has orders of magnitude fewer trainable parameters, is more robust to noise, and can generalize to previously unseen datasets. We extensively evaluate the quality of our registrations on diverse data. We demonstrate the robustness and generalizability of our model with in-the-wild face scans across different modalities, sensor types, and resolutions. Finally, we show that, by learning to register scans, SMF produces a hybrid linear and non-linear morphable model that can be used for generation, shape morphing, and expression transfer through manipulation of the latent space, including in-the-wild. We train SMF on a dataset of human faces comprising 9 large-scale databases on commodity hardware.
Geometrically Principled Connections in Graph Neural Networks
Apr 06, 2020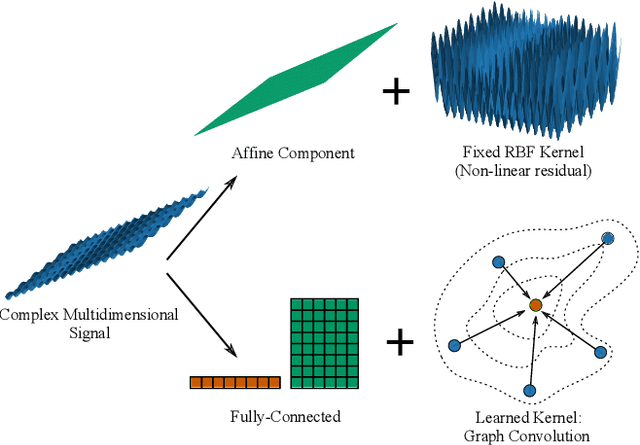
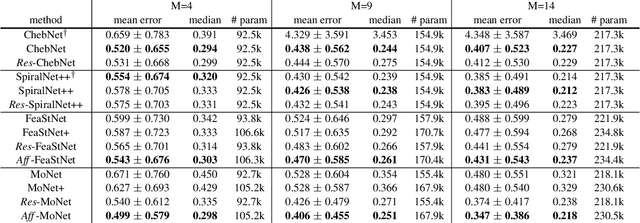
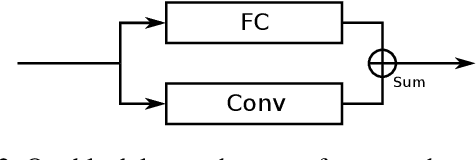
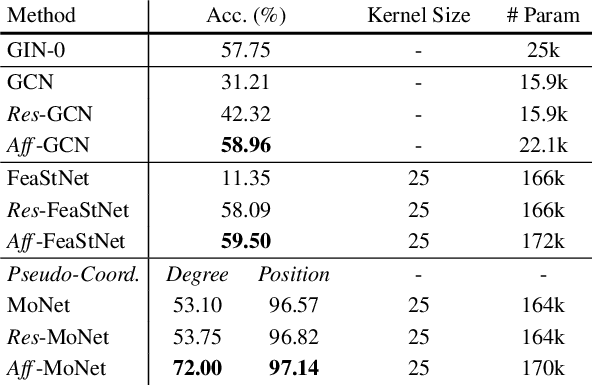
Graph convolution operators bring the advantages of deep learning to a variety of graph and mesh processing tasks previously deemed out of reach. With their continued success comes the desire to design more powerful architectures, often by adapting existing deep learning techniques to non-Euclidean data. In this paper, we argue geometry should remain the primary driving force behind innovation in the emerging field of geometric deep learning. We relate graph neural networks to widely successful computer graphics and data approximation models: radial basis functions (RBFs). We conjecture that, like RBFs, graph convolution layers would benefit from the addition of simple functions to the powerful convolution kernels. We introduce affine skip connections, a novel building block formed by combining a fully connected layer with any graph convolution operator. We experimentally demonstrate the effectiveness of our technique and show the improved performance is the consequence of more than the increased number of parameters. Operators equipped with the affine skip connection markedly outperform their base performance on every task we evaluated, i.e., shape reconstruction, dense shape correspondence, and graph classification. We hope our simple and effective approach will serve as a solid baseline and help ease future research in graph neural networks.
Robust Kronecker Component Analysis
Jan 18, 2018
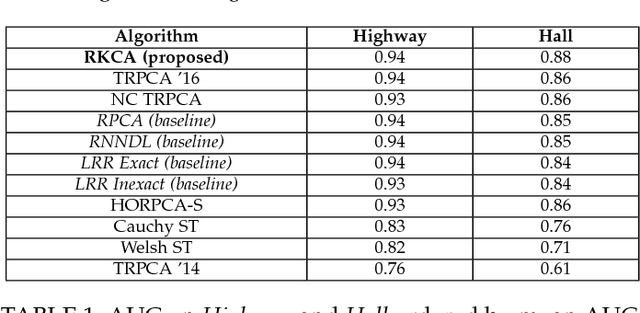
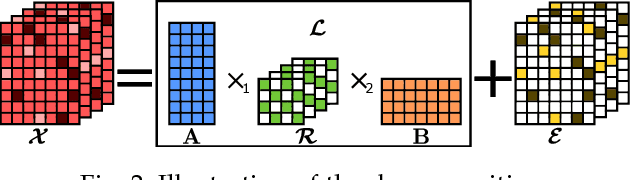
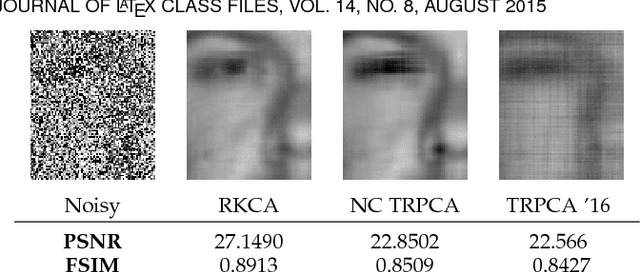
Dictionary learning and component analysis models are fundamental in learning compact representations that are relevant to a given task (feature extraction, dimensionality reduction, denoising, etc.). The model complexity is encoded by means of specific structure, such as sparsity, low-rankness, or nonnegativity. Unfortunately, approaches like K-SVD - that learn dictionaries for sparse coding via Singular Value Decomposition (SVD) - are hard to scale to high-volume and high-dimensional visual data, and fragile in the presence of outliers. Conversely, robust component analysis methods such as the Robust Principle Component Analysis (RPCA) are able to recover low-complexity (e.g., low-rank) representations from data corrupted with noise of unknown magnitude and support, but do not provide a dictionary that respects the structure of the data (e.g., images), and also involve expensive computations. In this paper, we propose a novel Kronecker-decomposable component analysis model, coined as Robust Kronecker Component Analysis (RKCA), that combines ideas from sparse dictionary learning and robust component analysis. RKCA has several appealing properties, including robustness to gross corruption; it can be used for low-rank modeling, and leverages separability to solve significantly smaller problems. We design an efficient learning algorithm by drawing links with a restricted form of tensor factorization, and analyze its optimality and low-rankness properties. The effectiveness of the proposed approach is demonstrated on real-world applications, namely background subtraction and image denoising and completion, by performing a thorough comparison with the current state of the art.
Robust Kronecker-Decomposable Component Analysis for Low-Rank Modeling
Jul 26, 2017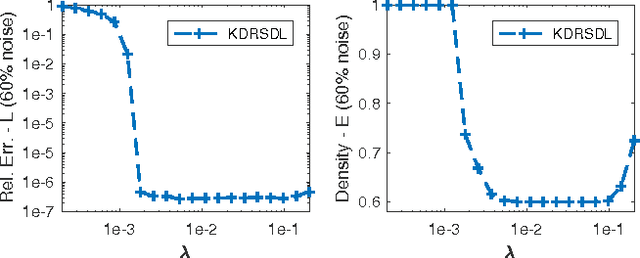
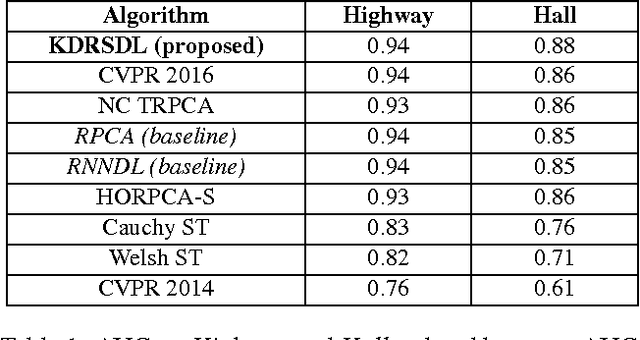

Dictionary learning and component analysis are part of one of the most well-studied and active research fields, at the intersection of signal and image processing, computer vision, and statistical machine learning. In dictionary learning, the current methods of choice are arguably K-SVD and its variants, which learn a dictionary (i.e., a decomposition) for sparse coding via Singular Value Decomposition. In robust component analysis, leading methods derive from Principal Component Pursuit (PCP), which recovers a low-rank matrix from sparse corruptions of unknown magnitude and support. However, K-SVD is sensitive to the presence of noise and outliers in the training set. Additionally, PCP does not provide a dictionary that respects the structure of the data (e.g., images), and requires expensive SVD computations when solved by convex relaxation. In this paper, we introduce a new robust decomposition of images by combining ideas from sparse dictionary learning and PCP. We propose a novel Kronecker-decomposable component analysis which is robust to gross corruption, can be used for low-rank modeling, and leverages separability to solve significantly smaller problems. We design an efficient learning algorithm by drawing links with a restricted form of tensor factorization. The effectiveness of the proposed approach is demonstrated on real-world applications, namely background subtraction and image denoising, by performing a thorough comparison with the current state of the art.