 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetanetworks as Regulatory Operators: Learning to Edit for Requirement Compliance
Dec 17, 2025As machine learning models are increasingly deployed in high-stakes settings, e.g. as decision support systems in various societal sectors or in critical infrastructure, designers and auditors are facing the need to ensure that models satisfy a wider variety of requirements (e.g. compliance with regulations, fairness, computational constraints) beyond performance. Although most of them are the subject of ongoing studies, typical approaches face critical challenges: post-processing methods tend to compromise performance, which is often counteracted by fine-tuning or, worse, training from scratch, an often time-consuming or even unavailable strategy. This raises the following question: "Can we efficiently edit models to satisfy requirements, without sacrificing their utility?" In this work, we approach this with a unifying framework, in a data-driven manner, i.e. we learn to edit neural networks (NNs), where the editor is an NN itself - a graph metanetwork - and editing amounts to a single inference step. In particular, the metanetwork is trained on NN populations to minimise an objective consisting of two terms: the requirement to be enforced and the preservation of the NN's utility. We experiment with diverse tasks (the data minimisation principle, bias mitigation and weight pruning) improving the trade-offs between performance, requirement satisfaction and time efficiency compared to popular post-processing or re-training alternatives.
Scale Equivariant Graph Metanetworks
Jun 15, 2024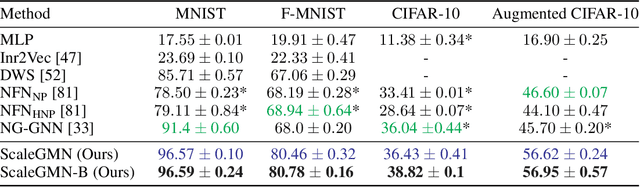
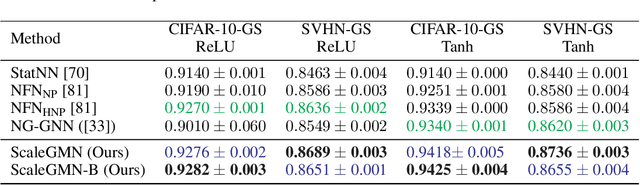
This paper pertains to an emerging machine learning paradigm: learning higher-order functions, i.e. functions whose inputs are functions themselves, $\textit{particularly when these inputs are Neural Networks (NNs)}$. With the growing interest in architectures that process NNs, a recurring design principle has permeated the field: adhering to the permutation symmetries arising from the connectionist structure of NNs. $\textit{However, are these the sole symmetries present in NN parameterizations}$? Zooming into most practical activation functions (e.g. sine, ReLU, tanh) answers this question negatively and gives rise to intriguing new symmetries, which we collectively refer to as $\textit{scaling symmetries}$, that is, non-zero scalar multiplications and divisions of weights and biases. In this work, we propose $\textit{Scale Equivariant Graph MetaNetworks - ScaleGMNs}$, a framework that adapts the Graph Metanetwork (message-passing) paradigm by incorporating scaling symmetries and thus rendering neuron and edge representations equivariant to valid scalings. We introduce novel building blocks, of independent technical interest, that allow for equivariance or invariance with respect to individual scalar multipliers or their product and use them in all components of ScaleGMN. Furthermore, we prove that, under certain expressivity conditions, ScaleGMN can simulate the forward and backward pass of any input feedforward neural network. Experimental results demonstrate that our method advances the state-of-the-art performance for several datasets and activation functions, highlighting the power of scaling symmetries as an inductive bias for NN processing.