 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclical Entropy Eruption: Entropy Dynamics in Agent Reinforcement Learning
May 27, 2026Agentic large language models are increasingly used to solve real-world tasks by reasoning over goals, invoking tools, and interacting with external environments. Reinforcement learning provides a natural framework for improving these behaviors, and recent agent RL methods have achieved strong results across domains. However, the training dynamics of agent RL remain poorly understood, limiting our ability to diagnose instabilities and design more effective training algorithms. In this work, we identify a previously underexplored phenomenon in agent RL, which we term cyclical entropy eruption. Unlike single-turn reasoning RL, where entropy typically collapses and stays low, agent RL training exhibits unique recurring cycles of sharp entropy eruption and gradual subsidence. We decompose this dynamic into three phases and provide theoretical and empirical analyses of each, explaining the mechanisms underlying its cyclical oscillation. We further show that degenerate patterns such as sentence duplication and hallucination, once acquired during eruption, can persist and accumulate across cycles. Motivated by these findings, we propose SEAL (Separation-Enhanced Agent Learning), a lightweight auxiliary loss that separates correct and incorrect trajectories in representation space, directly targeting the root cause of entropy eruption. Experiments across multiple benchmarks, models, and RL algorithms demonstrate that SEAL stabilizes training and yields stronger downstream agent performance.
How Do Transformers Learn to Associate Tokens: Gradient Leading Terms Bring Mechanistic Interpretability
Jan 27, 2026Semantic associations such as the link between "bird" and "flew" are foundational for language modeling as they enable models to go beyond memorization and instead generalize and generate coherent text. Understanding how these associations are learned and represented in language models is essential for connecting deep learning with linguistic theory and developing a mechanistic foundation for large language models. In this work, we analyze how these associations emerge from natural language data in attention-based language models through the lens of training dynamics. By leveraging a leading-term approximation of the gradients, we develop closed-form expressions for the weights at early stages of training that explain how semantic associations first take shape. Through our analysis, we reveal that each set of weights of the transformer has closed-form expressions as simple compositions of three basis functions (bigram, token-interchangeability, and context mappings), reflecting the statistics of the text corpus and uncovering how each component of the transformer captures semantic associations based on these compositions. Experiments on real-world LLMs demonstrate that our theoretical weight characterizations closely match the learned weights, and qualitative analyses further show how our theorem shines light on interpreting the learned associations in transformers.
How Well Can Preference Optimization Generalize Under Noisy Feedback?
Oct 01, 2025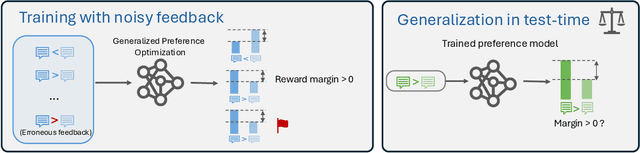

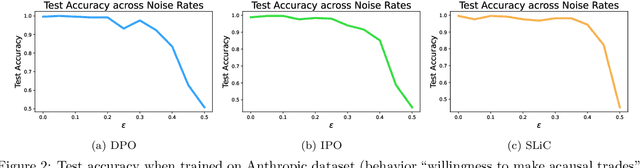
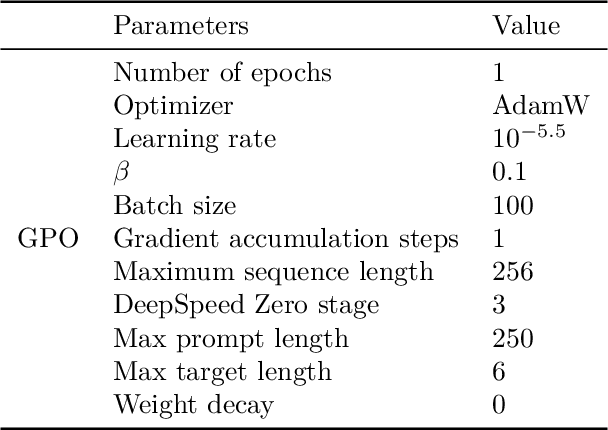
As large language models (LLMs) advance their capabilities, aligning these models with human preferences has become crucial. Preference optimization, which trains models to distinguish between preferred and non-preferred responses based on human feedback, has become a crucial component for aligning LLMs. However, most existing works assume noise-free feedback, which is unrealistic due to the inherent errors and inconsistencies in human judgments. This paper addresses the impact of noisy feedback on preference optimization, providing generalization guarantees under these conditions. In particular, we consider noise models that correspond to common real-world sources of noise, such as mislabeling and uncertainty. Unlike traditional analyses that assume convergence, our work focuses on finite-step preference optimization, offering new insights that are more aligned with practical LLM training. We describe how generalization decays with different types of noise across levels of noise rates based on the preference data distribution and number of samples. Our analysis for noisy preference learning applies to a broad family of preference optimization losses such as DPO, IPO, SLiC, etc. Empirical validation on contemporary LLMs confirms the practical relevance of our findings, offering valuable insights for developing AI systems that align with human preferences.
Towards Interpretability Without Sacrifice: Faithful Dense Layer Decomposition with Mixture of Decoders
May 27, 2025Multilayer perceptrons (MLPs) are an integral part of large language models, yet their dense representations render them difficult to understand, edit, and steer. Recent methods learn interpretable approximations via neuron-level sparsity, yet fail to faithfully reconstruct the original mapping--significantly increasing model's next-token cross-entropy loss. In this paper, we advocate for moving to layer-level sparsity to overcome the accuracy trade-off in sparse layer approximation. Under this paradigm, we introduce Mixture of Decoders (MxDs). MxDs generalize MLPs and Gated Linear Units, expanding pre-trained dense layers into tens of thousands of specialized sublayers. Through a flexible form of tensor factorization, each sparsely activating MxD sublayer implements a linear transformation with full-rank weights--preserving the original decoders' expressive capacity even under heavy sparsity. Experimentally, we show that MxDs significantly outperform state-of-the-art methods (e.g., Transcoders) on the sparsity-accuracy frontier in language models with up to 3B parameters. Further evaluations on sparse probing and feature steering demonstrate that MxDs learn similarly specialized features of natural language--opening up a promising new avenue for designing interpretable yet faithful decompositions. Our code is included at: https://github.com/james-oldfield/MxD/.
Visual Instruction Bottleneck Tuning
May 20, 2025Despite widespread adoption, multimodal large language models (MLLMs) suffer performance degradation when encountering unfamiliar queries under distribution shifts. Existing methods to improve MLLM generalization typically require either more instruction data or larger advanced model architectures, both of which incur non-trivial human labor or computational costs. In this work, we take an alternative approach to enhance the robustness of MLLMs under distribution shifts, from a representation learning perspective. Inspired by the information bottleneck (IB) principle, we derive a variational lower bound of the IB for MLLMs and devise a practical implementation, Visual Instruction Bottleneck Tuning (Vittle). We then provide a theoretical justification of Vittle by revealing its connection to an information-theoretic robustness metric of MLLM. Empirical validation of three MLLMs on open-ended and closed-form question answering and object hallucination detection tasks over 45 datasets, including 30 shift scenarios, demonstrates that Vittle consistently improves the MLLM's robustness under shifts by pursuing the learning of a minimal sufficient representation.
A Unified Understanding and Evaluation of Steering Methods
Feb 04, 2025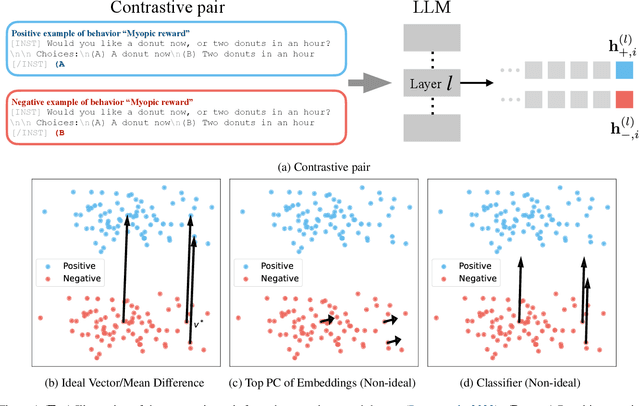
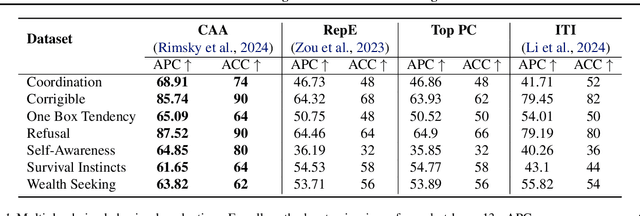
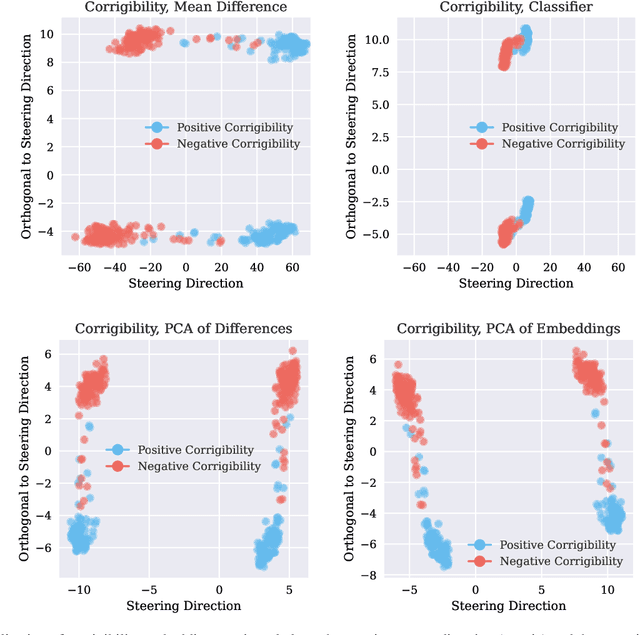
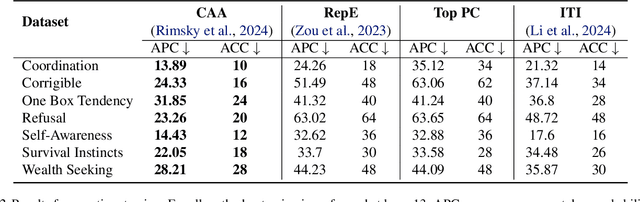
Steering methods provide a practical approach to controlling large language models by applying steering vectors to intermediate activations, guiding outputs toward desired behaviors while avoiding retraining. Despite their growing importance, the field lacks a unified understanding and consistent evaluation across tasks and datasets, hindering progress. This paper introduces a unified framework for analyzing and evaluating steering methods, formalizing their core principles and offering theoretical insights into their effectiveness. Through comprehensive empirical evaluations on multiple-choice and open-ended text generation tasks, we validate these insights, identifying key factors that influence performance and demonstrating the superiority of certain methods. Our work bridges theoretical and practical perspectives, offering actionable guidance for advancing the design, optimization, and deployment of steering methods in LLMs.
On the Generalization of Preference Learning with DPO
Aug 06, 2024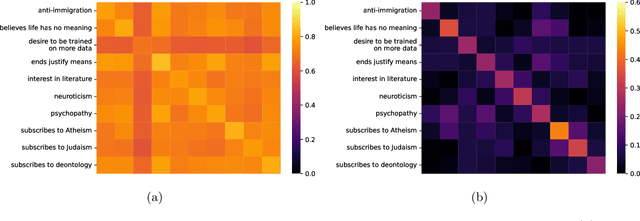
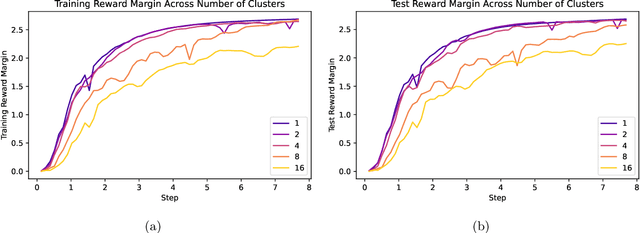
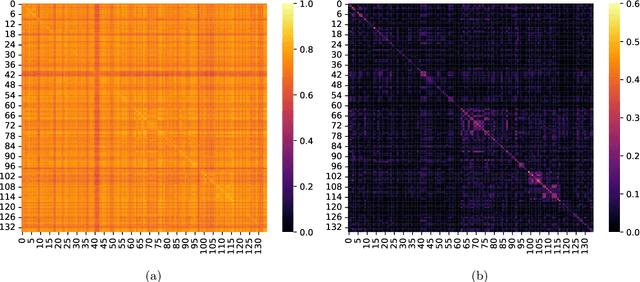
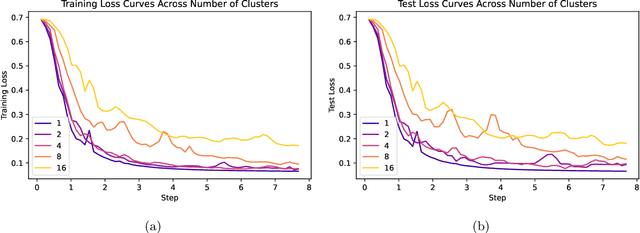
Large language models (LLMs) have demonstrated remarkable capabilities but often struggle to align with human preferences, leading to harmful or undesirable outputs. Preference learning, which trains models to distinguish between preferred and non-preferred responses based on human feedback, has become a crucial component for ensuring that LLMs align with human values. Despite the widespread adoption in real-world systems, a thorough theoretical understanding of the generalization guarantees for these models remain lacking. This paper bridges that gap by introducing a new theoretical framework to analyze the generalization guarantees of models trained with direct preference optimization (DPO). While existing generalization theory often focuses on overparameterized models achieving near-optimal loss or models independent of the training process, our framework rigorously assesses how well models generalize after a finite number of gradient steps, reflecting real-world LLM training practices. By analyzing the reward margin associated with each sample and its trajectory throughout training, we can effectively bound the generalization error. We derive learning guarantees showing that, under specific conditions, models trained with DPO can correctly discern preferred responses on unseen data with high probability. These insights are empirically validated on contemporary LLMs, underscoring the practical relevance of our theoretical findings.
Understanding the Learning Dynamics of Alignment with Human Feedback
Apr 08, 2024Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
Evaluating the Utility of Model Explanations for Model Development
Dec 10, 2023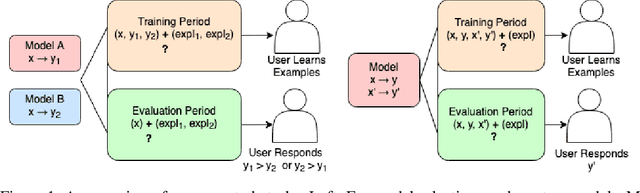
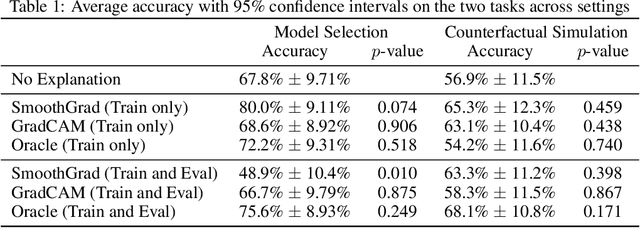

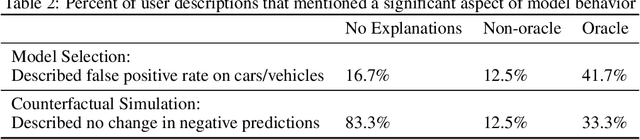
One of the motivations for explainable AI is to allow humans to make better and more informed decisions regarding the use and deployment of AI models. But careful evaluations are needed to assess whether this expectation has been fulfilled. Current evaluations mainly focus on algorithmic properties of explanations, and those that involve human subjects often employ subjective questions to test human's perception of explanation usefulness, without being grounded in objective metrics and measurements. In this work, we evaluate whether explanations can improve human decision-making in practical scenarios of machine learning model development. We conduct a mixed-methods user study involving image data to evaluate saliency maps generated by SmoothGrad, GradCAM, and an oracle explanation on two tasks: model selection and counterfactual simulation. To our surprise, we did not find evidence of significant improvement on these tasks when users were provided with any of the saliency maps, even the synthetic oracle explanation designed to be simple to understand and highly indicative of the answer. Nonetheless, explanations did help users more accurately describe the models. These findings suggest caution regarding the usefulness and potential for misunderstanding in saliency-based explanations.