 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContraCLIP: Interpretable GAN generation driven by pairs of contrasting sentences
Paper and Code
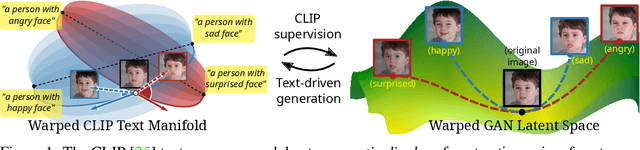
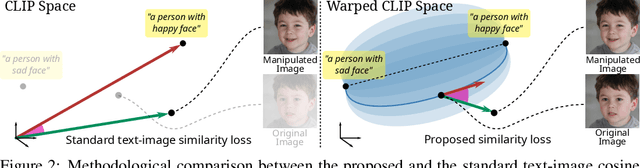

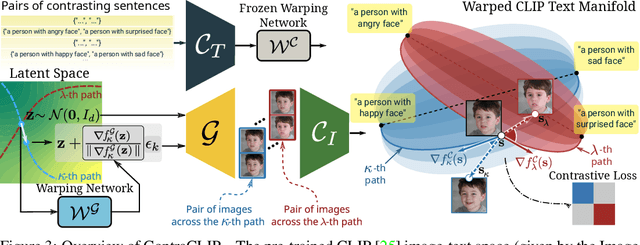
This work addresses the problem of discovering non-linear interpretable paths in the latent space of pre-trained GANs in a model-agnostic manner. In the proposed method, the discovery is driven by a set of pairs of natural language sentences with contrasting semantics, named semantic dipoles, that serve as the limits of the interpretation that we require by the trainable latent paths to encode. By using the pre-trained CLIP encoder, the sentences are projected into the vision-language space, where they serve as dipoles, and where RBF-based warping functions define a set of non-linear directional paths, one for each semantic dipole, allowing in this way traversals from one semantic pole to the other. By defining an objective that discovers paths in the latent space of GANs that generate changes along the desired paths in the vision-language embedding space, we provide an intuitive way of controlling the underlying generative factors and address some of the limitations of the state-of-the-art works, namely, that a) they are typically tailored to specific GAN architectures (i.e., StyleGAN), b) they disregard the relative position of the manipulated and the original image in the image embedding and the relative position of the image and the text embeddings, and c) they lead to abrupt image manipulations and quickly arrive at regions of low density and, thus, low image quality, providing limited control of the generative factors. We provide extensive qualitative and quantitative results that demonstrate our claims with two pre-trained GANs, and make the code and the pre-trained models publicly available at: https://github.com/chi0tzp/ContraCLIP