 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Attention for Efficient Bidirectional Sequence Modeling
Feb 22, 2025Transformers with linear attention enable fast and parallel training. Moreover, they can be formulated as Recurrent Neural Networks (RNNs), for efficient linear-time inference. While extensively evaluated in causal sequence modeling, they have yet to be extended to the bidirectional setting. This work introduces the LION framework, establishing new theoretical foundations for linear transformers in bidirectional sequence modeling. LION constructs a bidirectional RNN equivalent to full Linear Attention. This extends the benefits of linear transformers: parallel training, and efficient inference, into the bidirectional setting. Using LION, we cast three linear transformers to their bidirectional form: LION-LIT, the bidirectional variant corresponding to (Katharopoulos et al., 2020); LION-D, extending RetNet (Sun et al., 2023); and LION-S, a linear transformer with a stable selective mask inspired by selectivity of SSMs (Dao & Gu, 2024). Replacing the attention block with LION (-LIT, -D, -S) achieves performance on bidirectional tasks that approaches that of Transformers and State-Space Models (SSMs), while delivering significant improvements in training speed. Our implementation is available in http://github.com/LIONS-EPFL/LION.
Single-pass Detection of Jailbreaking Input in Large Language Models
Feb 21, 2025Defending aligned Large Language Models (LLMs) against jailbreaking attacks is a challenging problem, with existing approaches requiring multiple requests or even queries to auxiliary LLMs, making them computationally heavy. Instead, we focus on detecting jailbreaking input in a single forward pass. Our method, called Single Pass Detection SPD, leverages the information carried by the logits to predict whether the output sentence will be harmful. This allows us to defend in just one forward pass. SPD can not only detect attacks effectively on open-source models, but also minimizes the misclassification of harmless inputs. Furthermore, we show that SPD remains effective even without complete logit access in GPT-3.5 and GPT-4. We believe that our proposed method offers a promising approach to efficiently safeguard LLMs against adversarial attacks.
Certified Robustness Under Bounded Levenshtein Distance
Jan 23, 2025



Text classifiers suffer from small perturbations, that if chosen adversarially, can dramatically change the output of the model. Verification methods can provide robustness certificates against such adversarial perturbations, by computing a sound lower bound on the robust accuracy. Nevertheless, existing verification methods incur in prohibitive costs and cannot practically handle Levenshtein distance constraints. We propose the first method for computing the Lipschitz constant of convolutional classifiers with respect to the Levenshtein distance. We use these Lipschitz constant estimates for training 1-Lipschitz classifiers. This enables computing the certified radius of a classifier in a single forward pass. Our method, LipsLev, is able to obtain $38.80$% and $13.93$% verified accuracy at distance $1$ and $2$ respectively in the AG-News dataset, while being $4$ orders of magnitude faster than existing approaches. We believe our work can open the door to more efficient verification in the text domain.
Membership Inference Attacks against Large Vision-Language Models
Nov 05, 2024



Large vision-language models (VLLMs) exhibit promising capabilities for processing multi-modal tasks across various application scenarios. However, their emergence also raises significant data security concerns, given the potential inclusion of sensitive information, such as private photos and medical records, in their training datasets. Detecting inappropriately used data in VLLMs remains a critical and unresolved issue, mainly due to the lack of standardized datasets and suitable methodologies. In this study, we introduce the first membership inference attack (MIA) benchmark tailored for various VLLMs to facilitate training data detection. Then, we propose a novel MIA pipeline specifically designed for token-level image detection. Lastly, we present a new metric called MaxR\'enyi-K%, which is based on the confidence of the model output and applies to both text and image data. We believe that our work can deepen the understanding and methodology of MIAs in the context of VLLMs. Our code and datasets are available at https://github.com/LIONS-EPFL/VL-MIA.
Revisiting character-level adversarial attacks
May 07, 2024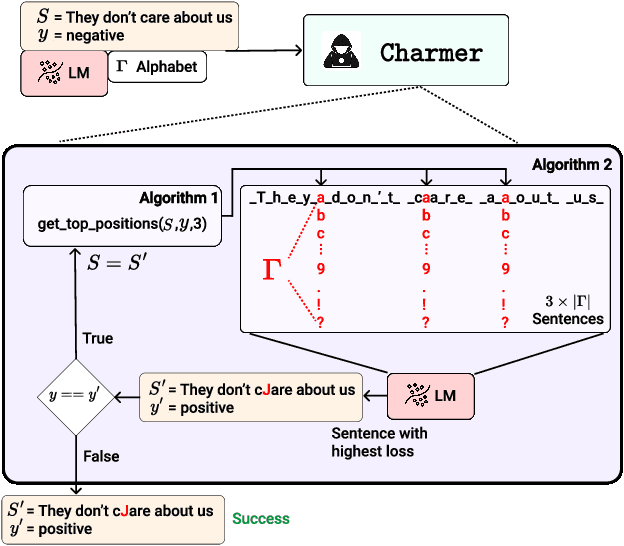

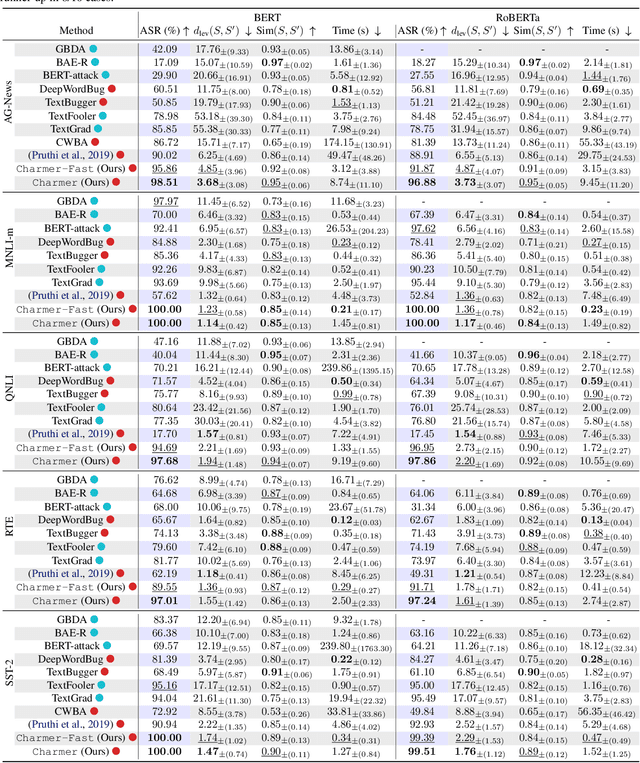
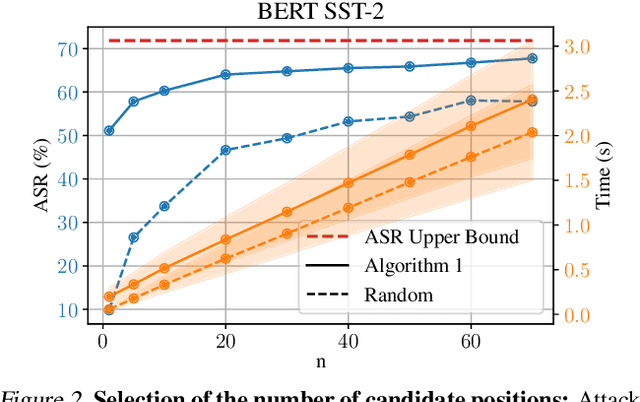
Adversarial attacks in Natural Language Processing apply perturbations in the character or token levels. Token-level attacks, gaining prominence for their use of gradient-based methods, are susceptible to altering sentence semantics, leading to invalid adversarial examples. While character-level attacks easily maintain semantics, they have received less attention as they cannot easily adopt popular gradient-based methods, and are thought to be easy to defend. Challenging these beliefs, we introduce Charmer, an efficient query-based adversarial attack capable of achieving high attack success rate (ASR) while generating highly similar adversarial examples. Our method successfully targets both small (BERT) and large (Llama 2) models. Specifically, on BERT with SST-2, Charmer improves the ASR in 4.84% points and the USE similarity in 8% points with respect to the previous art. Our implementation is available in https://github.com/LIONS-EPFL/Charmer.
Efficient local linearity regularization to overcome catastrophic overfitting
Jan 21, 2024Catastrophic overfitting (CO) in single-step adversarial training (AT) results in abrupt drops in the adversarial test accuracy (even down to 0%). For models trained with multi-step AT, it has been observed that the loss function behaves locally linearly with respect to the input, this is however lost in single-step AT. To address CO in single-step AT, several methods have been proposed to enforce local linearity of the loss via regularization. However, these regularization terms considerably slow down training due to Double Backpropagation. Instead, in this work, we introduce a regularization term, called ELLE, to mitigate CO effectively and efficiently in classical AT evaluations, as well as some more difficult regimes, e.g., large adversarial perturbations and long training schedules. Our regularization term can be theoretically linked to curvature of the loss function and is computationally cheaper than previous methods by avoiding Double Backpropagation. Our thorough experimental validation demonstrates that our work does not suffer from CO, even in challenging settings where previous works suffer from it. We also notice that adapting our regularization parameter during training (ELLE-A) greatly improves the performance, specially in large $\epsilon$ setups. Our implementation is available in https://github.com/LIONS-EPFL/ELLE .
Sound and Complete Verification of Polynomial Networks
Sep 15, 2022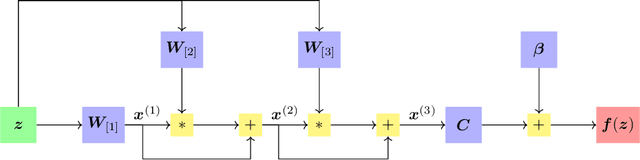
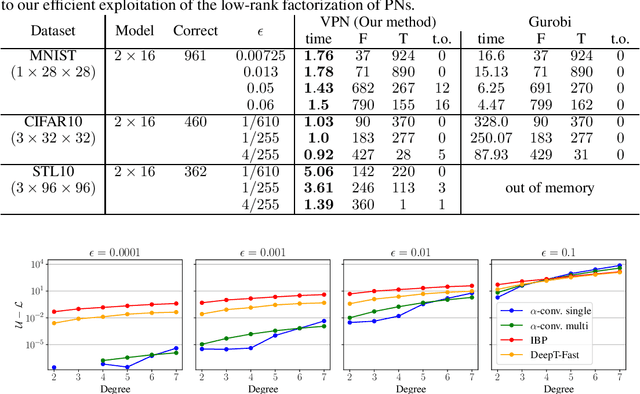
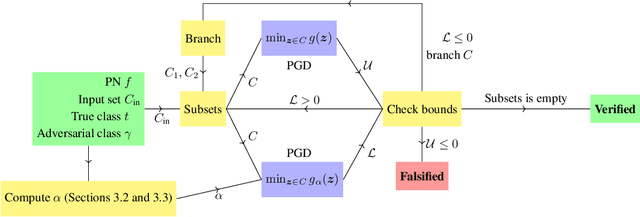
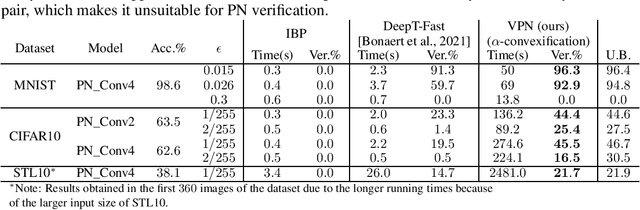
Polynomial Networks (PNs) have demonstrated promising performance on face and image recognition recently. However, robustness of PNs is unclear and thus obtaining certificates becomes imperative for enabling their adoption in real-world applications. Existing verification algorithms on ReLU neural networks (NNs) based on branch and bound (BaB) techniques cannot be trivially applied to PN verification. In this work, we devise a new bounding method, equipped with BaB for global convergence guarantees, called VPN. One key insight is that we obtain much tighter bounds than the interval bound propagation baseline. This enables sound and complete PN verification with empirical validation on MNIST, CIFAR10 and STL10 datasets. We believe our method has its own interest to NN verification.