 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Aware Semi-Supervised Learning for Comic Character Re-Identification
Aug 17, 2023Character re-identification, recognizing characters consistently across different panels in comics, presents significant challenges due to limited annotated data and complex variations in character appearances. To tackle this issue, we introduce a robust semi-supervised framework that combines metric learning with a novel 'Identity-Aware' self-supervision method by contrastive learning of face and body pairs of characters. Our approach involves processing both facial and bodily features within a unified network architecture, facilitating the extraction of identity-aligned character embeddings that capture individual identities while preserving the effectiveness of face and body features. This integrated character representation enhances feature extraction and improves character re-identification compared to re-identification by face or body independently, offering a parameter-efficient solution. By extensively validating our method using in-series and inter-series evaluation metrics, we demonstrate its effectiveness in consistently re-identifying comic characters. Compared to existing methods, our approach not only addresses the challenge of character re-identification but also serves as a foundation for downstream tasks since it can produce character embeddings without restrictions of face and body availability, enriching the comprehension of comic books. In our experiments, we leverage two newly curated datasets: the 'Comic Character Instances Dataset', comprising over a million character instances and the 'Comic Sequence Identity Dataset', containing annotations of identities within more than 3000 sets of four consecutive comic panels that we collected.
A Comprehensive Gold Standard and Benchmark for Comics Text Detection and Recognition
Dec 27, 2022



This study focuses on improving the optical character recognition (OCR) data for panels in the COMICS dataset, the largest dataset containing text and images from comic books. To do this, we developed a pipeline for OCR processing and labeling of comic books and created the first text detection and recognition datasets for western comics, called "COMICS Text+: Detection" and "COMICS Text+: Recognition". We evaluated the performance of state-of-the-art text detection and recognition models on these datasets and found significant improvement in word accuracy and normalized edit distance compared to the text in COMICS. We also created a new dataset called "COMICS Text+", which contains the extracted text from the textboxes in the COMICS dataset. Using the improved text data of COMICS Text+ in the comics processing model from resulted in state-of-the-art performance on cloze-style tasks without changing the model architecture. The COMICS Text+ dataset can be a valuable resource for researchers working on tasks including text detection, recognition, and high-level processing of comics, such as narrative understanding, character relations, and story generation. All the data and inference instructions can be accessed in https://github.com/gsoykan/comics_text_plus.
Domain-Adaptive Self-Supervised Pre-Training for Face & Body Detection in Drawings
Nov 19, 2022Drawings are powerful means of pictorial abstraction and communication. Understanding diverse forms of drawings, including digital arts, cartoons, and comics, has been a major problem of interest for the computer vision and computer graphics communities. Although there are large amounts of digitized drawings from comic books and cartoons, they contain vast stylistic variations, which necessitate expensive manual labeling for training domain-specific recognizers. In this work, we show how self-supervised learning, based on a teacher-student network with a modified student network update design, can be used to build face and body detectors. Our setup allows exploiting large amounts of unlabeled data from the target domain when labels are provided for only a small subset of it. We further demonstrate that style transfer can be incorporated into our learning pipeline to bootstrap detectors using a vast amount of out-of-domain labeled images from natural images (i.e., images from the real world). Our combined architecture yields detectors with state-of-the-art (SOTA) and near-SOTA performance using minimal annotation effort.
Active Scene Learning
Mar 07, 2019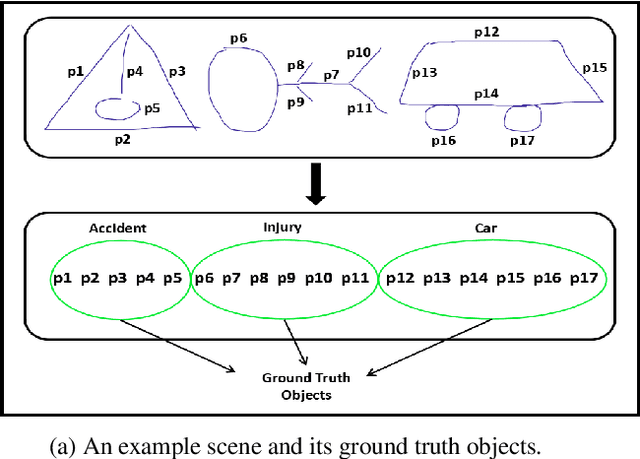



Sketch recognition allows natural and efficient interaction in pen-based interfaces. A key obstacle to building accurate sketch recognizers has been the difficulty of creating large amounts of annotated training data. Several authors have attempted to address this issue by creating synthetic data, and by building tools that support efficient annotation. Two prominent sets of approaches stand out from the rest of the crowd. They use interim classifiers trained with a small set of labeled data to aid the labeling of the remainder of the data. The first set of approaches uses a classifier trained with a partially labeled dataset to automatically label unlabeled instances. The others, based on active learning, save annotation effort by giving priority to labeling informative data instances. The former is sub-optimal since it doesn't prioritize the order of labeling to favor informative instances, while the latter makes the strong assumption that unlabeled data comes in an already segmented form (i.e. the ink in the training data is already assembled into groups forming isolated object instances). In this paper, we propose an active learning framework that combines the strengths of these methods, while addressing their weaknesses. In particular, we propose two methods for deciding how batches of unsegmented sketch scenes should be labeled. The first method, scene-wise selection, assesses the informativeness of each drawing (sketch scene) as a whole, and asks the user to annotate all objects in the drawing. The latter, segment-wise selection, attempts more precise targeting to locate informative fragments of drawings for user labeling. We show that both selection schemes outperform random selection. Furthermore, we demonstrate that precise targeting yields superior performance. Overall, our approach allows reaching top accuracy figures with up to 30% savings in annotation cost.