 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetitions in AI -- Robustly Ranking Solvers Using Statistical Resampling
Aug 09, 2023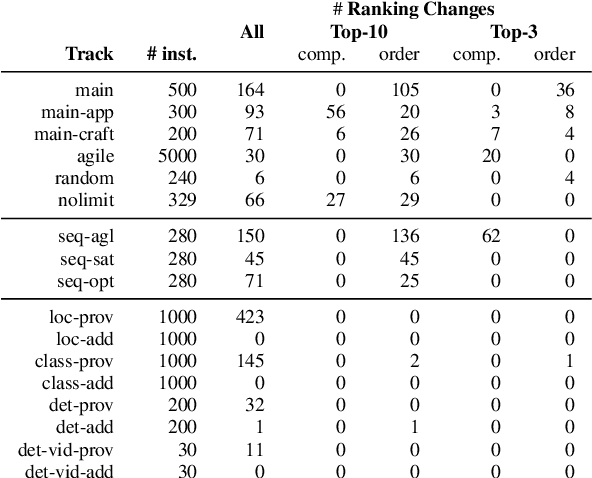
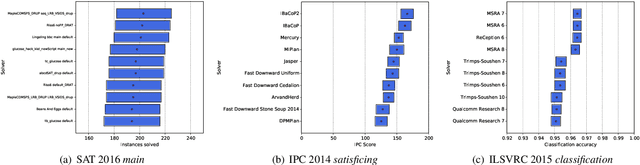
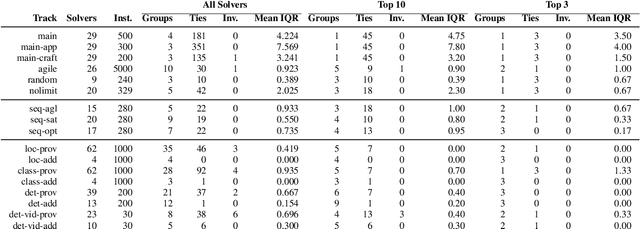

Solver competitions play a prominent role in assessing and advancing the state of the art for solving many problems in AI and beyond. Notably, in many areas of AI, competitions have had substantial impact in guiding research and applications for many years, and for a solver to be ranked highly in a competition carries considerable weight. But to which extent can we expect competition results to generalise to sets of problem instances different from those used in a particular competition? This is the question we investigate here, using statistical resampling techniques. We show that the rankings resulting from the standard interpretation of competition results can be very sensitive to even minor changes in the benchmark instance set used as the basis for assessment and can therefore not be expected to carry over to other samples from the same underlying instance distribution. To address this problem, we introduce a novel approach to statistically meaningful analysis of competition results based on resampling performance data. Our approach produces confidence intervals of competition scores as well as statistically robust solver rankings with bounded error. Applied to recent SAT, AI planning and computer vision competitions, our analysis reveals frequent statistical ties in solver performance as well as some inversions of ranks compared to the official results based on simple scoring.
Hot-Rodding the Browser Engine: Automatic Configuration of JavaScript Compilers
Jul 11, 2017

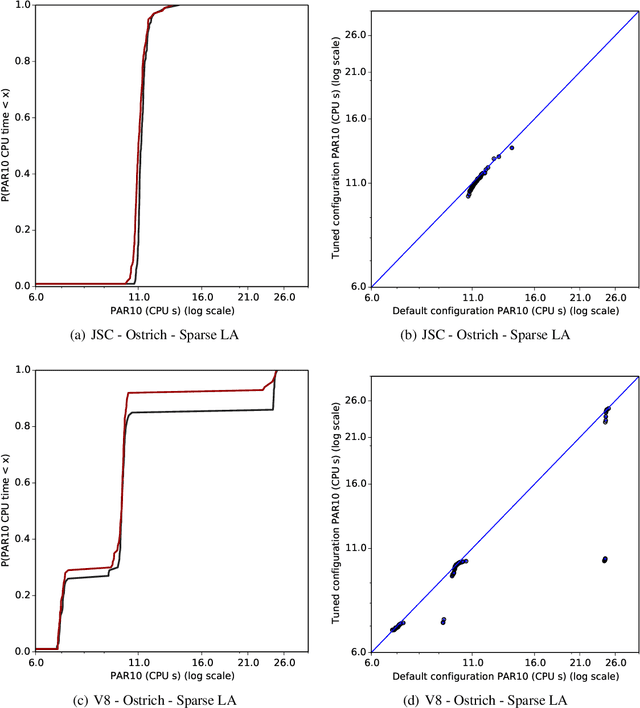

Modern software systems in many application areas offer to the user a multitude of parameters, switches and other customisation hooks. Humans tend to have difficulties determining the best configurations for particular applications. Modern optimising compilers are an example of such software systems; their many parameters need to be tuned for optimal performance, but are often left at the default values for convenience. In this work, we automatically determine compiler parameter settings that result in optimised performance for particular applications. Specifically, we apply a state-of-the-art automated parameter configuration procedure based on cutting-edge machine learning and optimisation techniques to two prominent JavaScript compilers and demonstrate that significant performance improvements, more than 35% in some cases, can be achieved over the default parameter settings on a diverse set of benchmarks.