 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Seamless Borders: A Method for Mitigating Inconsistencies in Image Inpainting and Outpainting
Jun 14, 2025Image inpainting is the task of reconstructing missing or damaged parts of an image in a way that seamlessly blends with the surrounding content. With the advent of advanced generative models, especially diffusion models and generative adversarial networks, inpainting has achieved remarkable improvements in visual quality and coherence. However, achieving seamless continuity remains a significant challenge. In this work, we propose two novel methods to address discrepancy issues in diffusion-based inpainting models. First, we introduce a modified Variational Autoencoder that corrects color imbalances, ensuring that the final inpainted results are free of color mismatches. Second, we propose a two-step training strategy that improves the blending of generated and existing image content during the diffusion process. Through extensive experiments, we demonstrate that our methods effectively reduce discontinuity and produce high-quality inpainting results that are coherent and visually appealing.
See Further When Clear: Curriculum Consistency Model
Dec 09, 2024



Significant advances have been made in the sampling efficiency of diffusion models and flow matching models, driven by Consistency Distillation (CD), which trains a student model to mimic the output of a teacher model at a later timestep. However, we found that the learning complexity of the student model varies significantly across different timesteps, leading to suboptimal performance in CD.To address this issue, we propose the Curriculum Consistency Model (CCM), which stabilizes and balances the learning complexity across timesteps. Specifically, we regard the distillation process at each timestep as a curriculum and introduce a metric based on Peak Signal-to-Noise Ratio (PSNR) to quantify the learning complexity of this curriculum, then ensure that the curriculum maintains consistent learning complexity across different timesteps by having the teacher model iterate more steps when the noise intensity is low. Our method achieves competitive single-step sampling Fr\'echet Inception Distance (FID) scores of 1.64 on CIFAR-10 and 2.18 on ImageNet 64x64.Moreover, we have extended our method to large-scale text-to-image models and confirmed that it generalizes well to both diffusion models (Stable Diffusion XL) and flow matching models (Stable Diffusion 3). The generated samples demonstrate improved image-text alignment and semantic structure, since CCM enlarges the distillation step at large timesteps and reduces the accumulated error.
CDFGNN: a Systematic Design of Cache-based Distributed Full-Batch Graph Neural Network Training with Communication Reduction
Aug 01, 2024Graph neural network training is mainly categorized into mini-batch and full-batch training methods. The mini-batch training method samples subgraphs from the original graph in each iteration. This sampling operation introduces extra computation overhead and reduces the training accuracy. Meanwhile, the full-batch training method calculates the features and corresponding gradients of all vertices in each iteration, and therefore has higher convergence accuracy. However, in the distributed cluster, frequent remote accesses of vertex features and gradients lead to huge communication overhead, thus restricting the overall training efficiency. In this paper, we introduce the cached-based distributed full-batch graph neural network training framework (CDFGNN). We propose the adaptive cache mechanism to reduce the remote vertex access by caching the historical features and gradients of neighbor vertices. Besides, we further optimize the communication overhead by quantifying the messages and designing the graph partition algorithm for the hierarchical communication architecture. Experiments show that the adaptive cache mechanism reduces remote vertex accesses by 63.14% on average. Combined with communication quantization and hierarchical GP algorithm, CDFGNN outperforms the state-of-the-art distributed full-batch training frameworks by 30.39% in our experiments. Our results indicate that CDFGNN has great potential in accelerating distributed full-batch GNN training tasks.
An Efficient Pruning Process with Locality Aware Exploration and Dynamic Graph Editing for Subgraph Matching
Dec 22, 2021
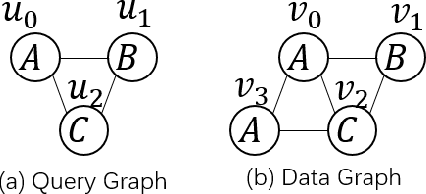
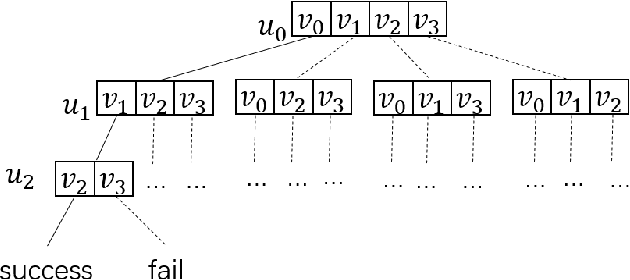
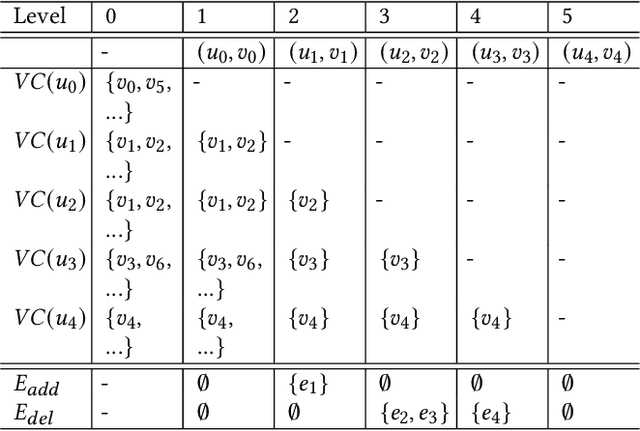
Subgraph matching is a NP-complete problem that extracts isomorphic embeddings of a query graph $q$ in a data graph $G$. In this paper, we present a framework with three components: Preprocessing, Reordering and Enumeration. While pruning is the core technique for almost all existing subgraph matching solvers, it mainly eliminates unnecessary enumeration over data graph without alternation of query graph. By formulating a problem: Assignment under Conditional Candidate Set(ACCS), which is proven to be equivalent to Subgraph matching problem, we propose Dynamic Graph Editing(DGE) that is for the first time designed to tailor the query graph to achieve pruning effect and performance acceleration. As a result, we proposed DGEE(Dynamic Graph Editing Enumeration), a novel enumeration algorithm combines Dynamic Graph Editing and Failing Set optimization. Our second contribution is proposing fGQL , an optimized version of GQL algorithm, that is utilized during the Preprocessing phase. Extensive experimental results show that the DGEE-based framework can outperform state-of-the-art subgraph matching algorithms.
Improving the Performance of Stochastic Local Search for Maximum Vertex Weight Clique Problem Using Programming by Optimization
Feb 27, 2020
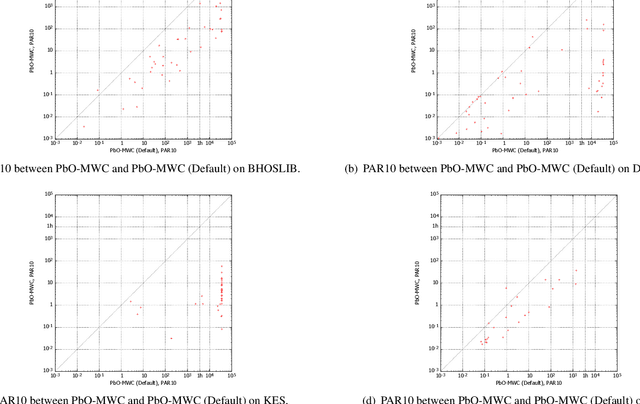


The maximum vertex weight clique problem (MVWCP) is an important generalization of the maximum clique problem (MCP) that has a wide range of real-world applications. In situations where rigorous guarantees regarding the optimality of solutions are not required, MVWCP is usually solved using stochastic local search (SLS) algorithms, which also define the state of the art for solving this problem. However, there is no single SLS algorithm which gives the best performance across all classes of MVWCP instances, and it is challenging to effectively identify the most suitable algorithm for each class of MVWCP instances. In this work, we follow the paradigm of Programming by Optimization (PbO) to develop a new, flexible and highly parametric SLS framework for solving MVWCP, combining, for the first time, a broad range of effective heuristic mechanisms. By automatically configuring this PbO-MWC framework, we achieve substantial advances in the state-of-the-art in solving MVWCP over a broad range of prominent benchmarks, including two derived from real-world applications in transplantation medicine (kidney exchange) and assessment of research excellence.
Utilizing the Instability in Weakly Supervised Object Detection
Jun 14, 2019

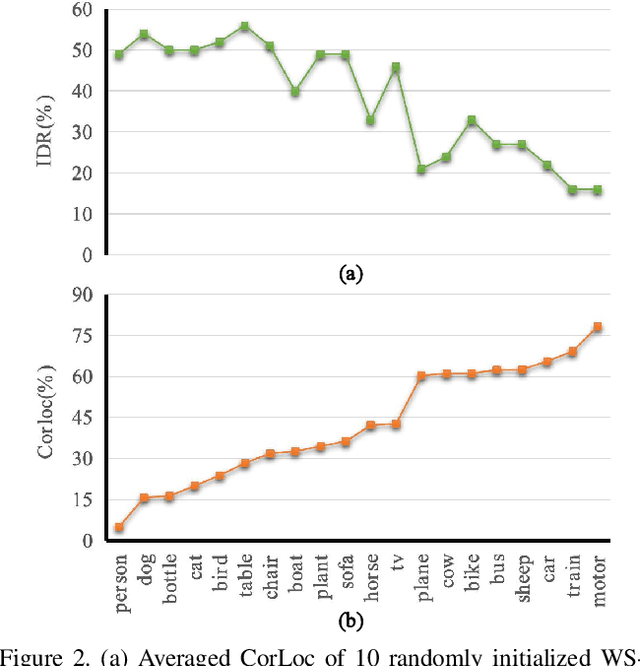

Weakly supervised object detection (WSOD) focuses on training object detector with only image-level annotations, and is challenging due to the gap between the supervision and the objective. Most of existing approaches model WSOD as a multiple instance learning (MIL) problem. However, we observe that the result of MIL based detector is unstable, i.e., the most confident bounding boxes change significantly when using different initializations. We quantitatively demonstrate the instability by introducing a metric to measure it, and empirically analyze the reason of instability. Although the instability seems harmful for detection task, we argue that it can be utilized to improve the performance by fusing the results of differently initialized detectors. To implement this idea, we propose an end-to-end framework with multiple detection branches, and introduce a simple fusion strategy. We further propose an orthogonal initialization method to increase the difference between detection branches. By utilizing the instability, we achieve 52.6% and 48.0% mAP on the challenging PASCAL VOC 2007 and 2012 datasets, which are both the new state-of-the-arts.