 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDFGNN: a Systematic Design of Cache-based Distributed Full-Batch Graph Neural Network Training with Communication Reduction
Aug 01, 2024Graph neural network training is mainly categorized into mini-batch and full-batch training methods. The mini-batch training method samples subgraphs from the original graph in each iteration. This sampling operation introduces extra computation overhead and reduces the training accuracy. Meanwhile, the full-batch training method calculates the features and corresponding gradients of all vertices in each iteration, and therefore has higher convergence accuracy. However, in the distributed cluster, frequent remote accesses of vertex features and gradients lead to huge communication overhead, thus restricting the overall training efficiency. In this paper, we introduce the cached-based distributed full-batch graph neural network training framework (CDFGNN). We propose the adaptive cache mechanism to reduce the remote vertex access by caching the historical features and gradients of neighbor vertices. Besides, we further optimize the communication overhead by quantifying the messages and designing the graph partition algorithm for the hierarchical communication architecture. Experiments show that the adaptive cache mechanism reduces remote vertex accesses by 63.14% on average. Combined with communication quantization and hierarchical GP algorithm, CDFGNN outperforms the state-of-the-art distributed full-batch training frameworks by 30.39% in our experiments. Our results indicate that CDFGNN has great potential in accelerating distributed full-batch GNN training tasks.
An Efficient Pruning Process with Locality Aware Exploration and Dynamic Graph Editing for Subgraph Matching
Dec 22, 2021
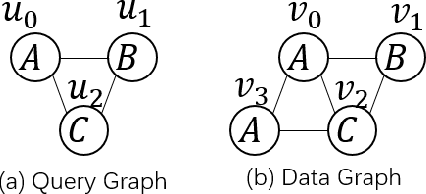
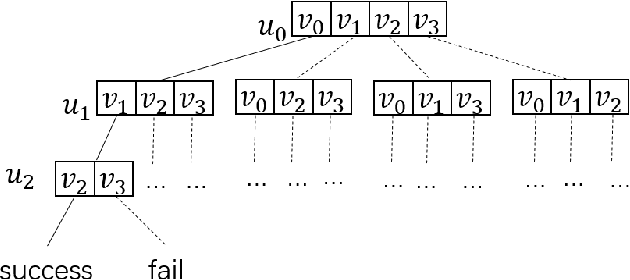
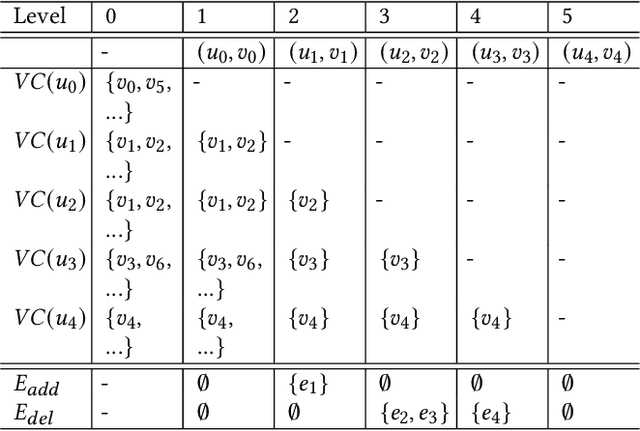
Subgraph matching is a NP-complete problem that extracts isomorphic embeddings of a query graph $q$ in a data graph $G$. In this paper, we present a framework with three components: Preprocessing, Reordering and Enumeration. While pruning is the core technique for almost all existing subgraph matching solvers, it mainly eliminates unnecessary enumeration over data graph without alternation of query graph. By formulating a problem: Assignment under Conditional Candidate Set(ACCS), which is proven to be equivalent to Subgraph matching problem, we propose Dynamic Graph Editing(DGE) that is for the first time designed to tailor the query graph to achieve pruning effect and performance acceleration. As a result, we proposed DGEE(Dynamic Graph Editing Enumeration), a novel enumeration algorithm combines Dynamic Graph Editing and Failing Set optimization. Our second contribution is proposing fGQL , an optimized version of GQL algorithm, that is utilized during the Preprocessing phase. Extensive experimental results show that the DGEE-based framework can outperform state-of-the-art subgraph matching algorithms.