 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Seamless Borders: A Method for Mitigating Inconsistencies in Image Inpainting and Outpainting
Jun 14, 2025Image inpainting is the task of reconstructing missing or damaged parts of an image in a way that seamlessly blends with the surrounding content. With the advent of advanced generative models, especially diffusion models and generative adversarial networks, inpainting has achieved remarkable improvements in visual quality and coherence. However, achieving seamless continuity remains a significant challenge. In this work, we propose two novel methods to address discrepancy issues in diffusion-based inpainting models. First, we introduce a modified Variational Autoencoder that corrects color imbalances, ensuring that the final inpainted results are free of color mismatches. Second, we propose a two-step training strategy that improves the blending of generated and existing image content during the diffusion process. Through extensive experiments, we demonstrate that our methods effectively reduce discontinuity and produce high-quality inpainting results that are coherent and visually appealing.
See Further When Clear: Curriculum Consistency Model
Dec 09, 2024



Significant advances have been made in the sampling efficiency of diffusion models and flow matching models, driven by Consistency Distillation (CD), which trains a student model to mimic the output of a teacher model at a later timestep. However, we found that the learning complexity of the student model varies significantly across different timesteps, leading to suboptimal performance in CD.To address this issue, we propose the Curriculum Consistency Model (CCM), which stabilizes and balances the learning complexity across timesteps. Specifically, we regard the distillation process at each timestep as a curriculum and introduce a metric based on Peak Signal-to-Noise Ratio (PSNR) to quantify the learning complexity of this curriculum, then ensure that the curriculum maintains consistent learning complexity across different timesteps by having the teacher model iterate more steps when the noise intensity is low. Our method achieves competitive single-step sampling Fr\'echet Inception Distance (FID) scores of 1.64 on CIFAR-10 and 2.18 on ImageNet 64x64.Moreover, we have extended our method to large-scale text-to-image models and confirmed that it generalizes well to both diffusion models (Stable Diffusion XL) and flow matching models (Stable Diffusion 3). The generated samples demonstrate improved image-text alignment and semantic structure, since CCM enlarges the distillation step at large timesteps and reduces the accumulated error.
An Efficient Pruning Process with Locality Aware Exploration and Dynamic Graph Editing for Subgraph Matching
Dec 22, 2021
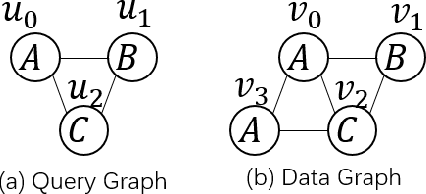
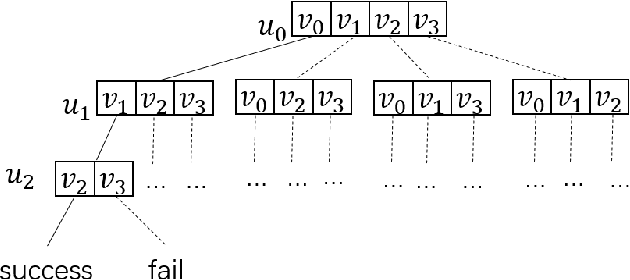
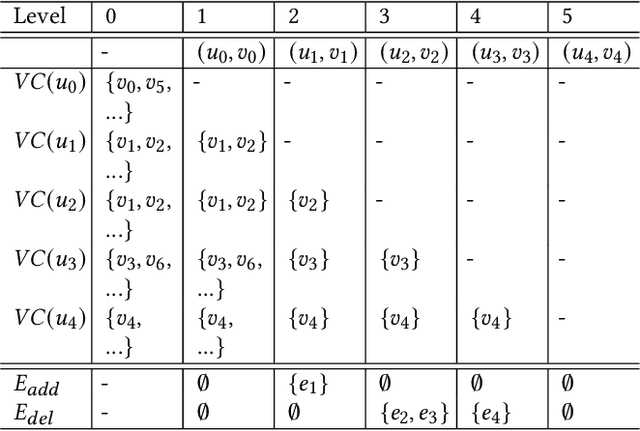
Subgraph matching is a NP-complete problem that extracts isomorphic embeddings of a query graph $q$ in a data graph $G$. In this paper, we present a framework with three components: Preprocessing, Reordering and Enumeration. While pruning is the core technique for almost all existing subgraph matching solvers, it mainly eliminates unnecessary enumeration over data graph without alternation of query graph. By formulating a problem: Assignment under Conditional Candidate Set(ACCS), which is proven to be equivalent to Subgraph matching problem, we propose Dynamic Graph Editing(DGE) that is for the first time designed to tailor the query graph to achieve pruning effect and performance acceleration. As a result, we proposed DGEE(Dynamic Graph Editing Enumeration), a novel enumeration algorithm combines Dynamic Graph Editing and Failing Set optimization. Our second contribution is proposing fGQL , an optimized version of GQL algorithm, that is utilized during the Preprocessing phase. Extensive experimental results show that the DGEE-based framework can outperform state-of-the-art subgraph matching algorithms.