 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Curves for Decision Making in Supervised Machine Learning -- A Survey
Paper and Code
Jan 28, 2022
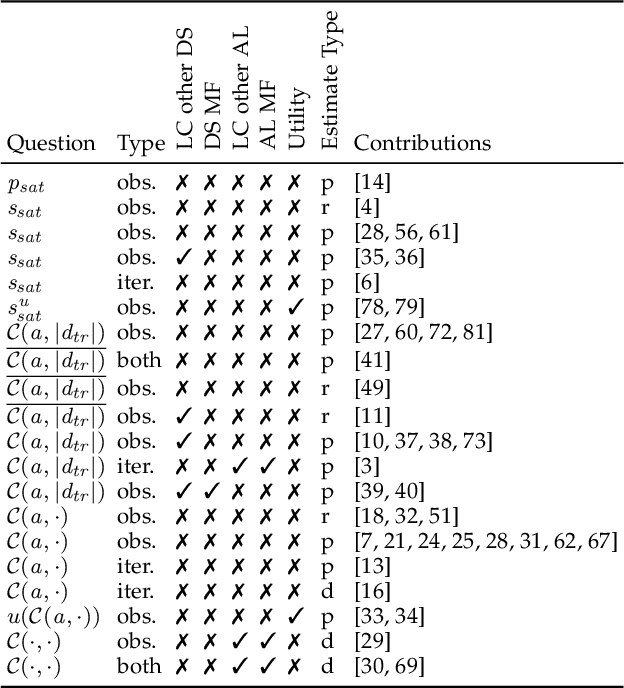


Learning curves are a concept from social sciences that has been adopted in the context of machine learning to assess the performance of a learning algorithm with respect to a certain resource, e.g. the number of training examples or the number of training iterations. Learning curves have important applications in several contexts of machine learning, most importantly for the context of data acquisition, early stopping of model training and model selection. For example, by modelling the learning curves, one can assess at an early stage whether the algorithm and hyperparameter configuration have the potential to be a suitable choice, often speeding up the algorithm selection process. A variety of approaches has been proposed to use learning curves for decision making. Some models answer the binary decision question of whether a certain algorithm at a certain budget will outperform a certain reference performance, whereas more complex models predict the entire learning curve of an algorithm. We contribute a framework that categorizes learning curve approaches using three criteria: the decision situation that they address, the intrinsic learning curve question that they answer and the type of resources that they use. We survey papers from literature and classify them into this framework.