 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Informative Model Selection using Learning Curve Cross-Validation
Paper and Code


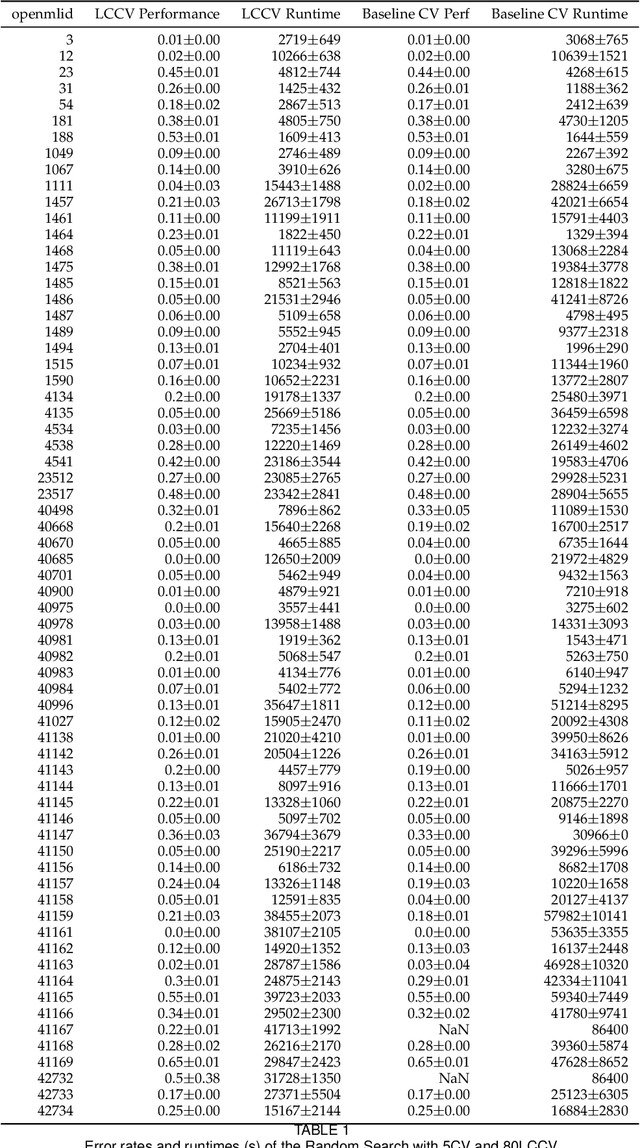
Common cross-validation (CV) methods like k-fold cross-validation or Monte-Carlo cross-validation estimate the predictive performance of a learner by repeatedly training it on a large portion of the given data and testing on the remaining data. These techniques have two major drawbacks. First, they can be unnecessarily slow on large datasets. Second, beyond an estimation of the final performance, they give almost no insights into the learning process of the validated algorithm. In this paper, we present a new approach for validation based on learning curves (LCCV). Instead of creating train-test splits with a large portion of training data, LCCV iteratively increases the number of instances used for training. In the context of model selection, it discards models that are very unlikely to become competitive. We run a large scale experiment on the 67 datasets from the AutoML benchmark and empirically show that in over 90% of the cases using LCCV leads to similar performance (at most 1.5% difference) as using 5/10-fold CV. However, it yields substantial runtime reductions of over 20% on average. Additionally, it provides important insights, which for example allow assessing the benefits of acquiring more data. These results are orthogonal to other advances in the field of AutoML.