 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Compression for Tabular Foundation Models
Feb 05, 2026The long-standing dominance of gradient-boosted decision trees for tabular data has recently been challenged by in-context learning tabular foundation models. In-context learning methods fit and predict in one forward pass without parameter updates by leveraging the training data as context for predicting on query test points. While recent tabular foundation models achieve state-of-the-art performance, their transformer architecture based on the attention mechanism has quadratic complexity regarding dataset size, which in turn increases the overhead on training and inference time, and limits the capacity of the models to handle large-scale datasets. In this work, we propose TACO, an end-to-end tabular compression model that compresses the training dataset in a latent space. We test our method on the TabArena benchmark, where our proposed method is up to 94x faster in inference time, while consuming up to 97\% less memory compared to the state-of-the-art tabular transformer architecture, all while retaining performance without significant degradation. Lastly, our method not only scales better with increased dataset sizes, but it also achieves better performance compared to other baselines.
Tabular Data: Is Attention All You Need?
Feb 06, 2024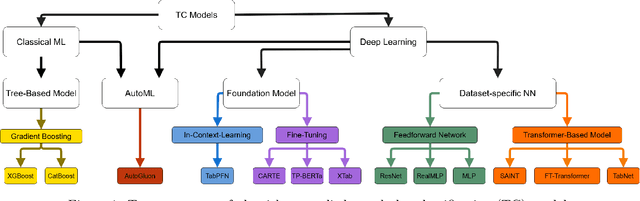
Deep Learning has revolutionized the field of AI and led to remarkable achievements in applications involving image and text data. Unfortunately, there is inconclusive evidence on the merits of neural networks for structured tabular data. In this paper, we introduce a large-scale empirical study comparing neural networks against gradient-boosted decision trees on tabular data, but also transformer-based architectures against traditional multi-layer perceptrons (MLP) with residual connections. In contrast to prior work, our empirical findings indicate that neural networks are competitive against decision trees. Furthermore, we assess that transformer-based architectures do not outperform simpler variants of traditional MLP architectures on tabular datasets. As a result, this paper helps the research and practitioner communities make informed choices on deploying neural networks on future tabular data applications.