 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoints2Polygons: Context-Based Segmentation from Weak Labels Using Adversarial Networks
Paper and Code
Jun 05, 2021
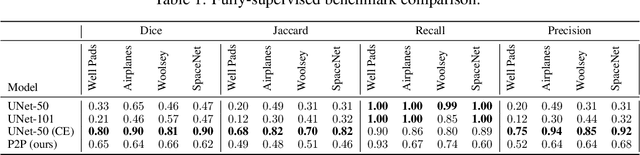
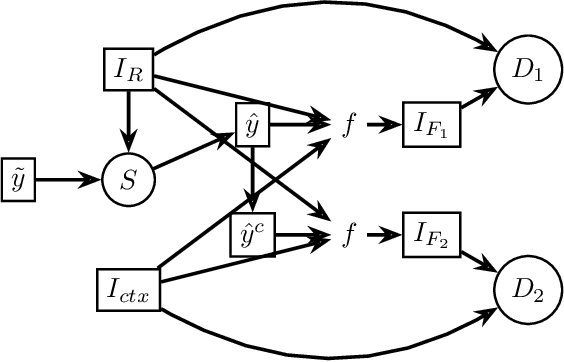
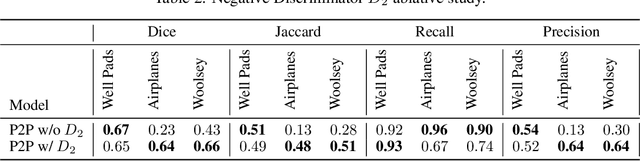
In applied image segmentation tasks, the ability to provide numerous and precise labels for training is paramount to the accuracy of the model at inference time. However, this overhead is often neglected, and recently proposed segmentation architectures rely heavily on the availability and fidelity of ground truth labels to achieve state-of-the-art accuracies. Failure to acknowledge the difficulty in creating adequate ground truths can lead to an over-reliance on pre-trained models or a lack of adoption in real-world applications. We introduce Points2Polygons (P2P), a model which makes use of contextual metric learning techniques that directly addresses this problem. Points2Polygons performs well against existing fully-supervised segmentation baselines with limited training data, despite using lightweight segmentation models (U-Net with a ResNet18 backbone) and having access to only weak labels in the form of object centroids and no pre-training. We demonstrate this on several different small but non-trivial datasets. We show that metric learning using contextual data provides key insights for self-supervised tasks in general, and allow segmentation models to easily generalize across traditionally label-intensive domains in computer vision.