 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA blind spot for large language models: Supradiegetic linguistic information
Jun 11, 2023



Large Language Models (LLMs) like ChatGPT reflect profound changes in the field of Artificial Intelligence, achieving a linguistic fluency that is impressively, even shockingly, human-like. The extent of their current and potential capabilities is an active area of investigation by no means limited to scientific researchers. It is common for people to frame the training data for LLMs as "text" or even "language". We examine the details of this framing using ideas from several areas, including linguistics, embodied cognition, cognitive science, mathematics, and history. We propose that considering what it is like to be an LLM like ChatGPT, as Nagel might have put it, can help us gain insight into its capabilities in general, and in particular, that its exposure to linguistic training data can be productively reframed as exposure to the diegetic information encoded in language, and its deficits can be reframed as ignorance of extradiegetic information, including supradiegetic linguistic information. Supradiegetic linguistic information consists of those arbitrary aspects of the physical form of language that are not derivable from the one-dimensional relations of context -- frequency, adjacency, proximity, co-occurrence -- that LLMs like ChatGPT have access to. Roughly speaking, the diegetic portion of a word can be thought of as its function, its meaning, as the information in a theoretical vector in a word embedding, while the supradiegetic portion of the word can be thought of as its form, like the shapes of its letters or the sounds of its syllables. We use these concepts to investigate why LLMs like ChatGPT have trouble handling palindromes, the visual characteristics of symbols, translating Sumerian cuneiform, and continuing integer sequences.
Augmenting semantic lexicons using word embeddings and transfer learning
Sep 18, 2021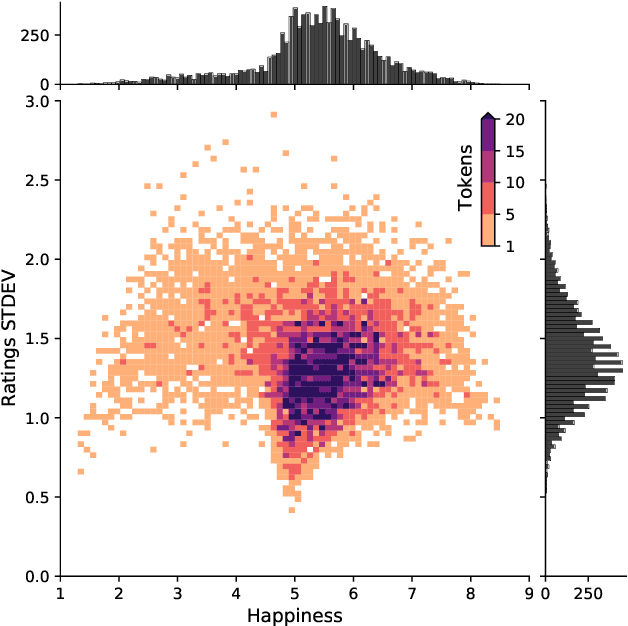
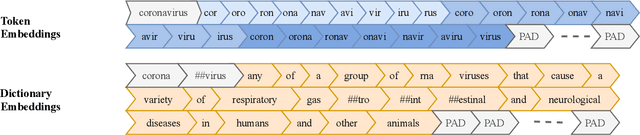
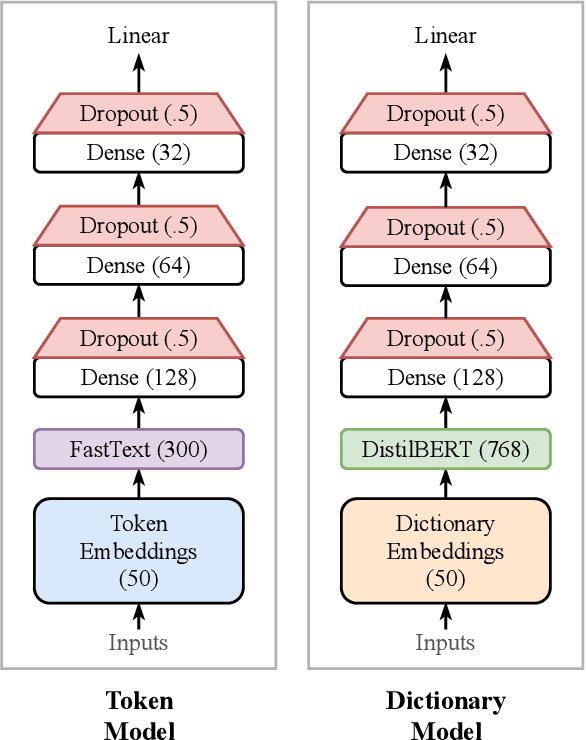
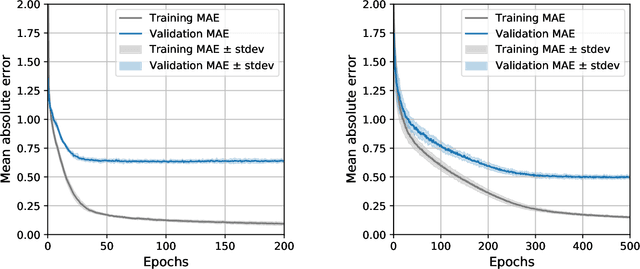
Sentiment-aware intelligent systems are essential to a wide array of applications including marketing, political campaigns, recommender systems, behavioral economics, social psychology, and national security. These sentiment-aware intelligent systems are driven by language models which broadly fall into two paradigms: 1. Lexicon-based and 2. Contextual. Although recent contextual models are increasingly dominant, we still see demand for lexicon-based models because of their interpretability and ease of use. For example, lexicon-based models allow researchers to readily determine which words and phrases contribute most to a change in measured sentiment. A challenge for any lexicon-based approach is that the lexicon needs to be routinely expanded with new words and expressions. Crowdsourcing annotations for semantic dictionaries may be an expensive and time-consuming task. Here, we propose two models for predicting sentiment scores to augment semantic lexicons at a relatively low cost using word embeddings and transfer learning. Our first model establishes a baseline employing a simple and shallow neural network initialized with pre-trained word embeddings using a non-contextual approach. Our second model improves upon our baseline, featuring a deep Transformer-based network that brings to bear word definitions to estimate their lexical polarity. Our evaluation shows that both models are able to score new words with a similar accuracy to reviewers from Amazon Mechanical Turk, but at a fraction of the cost.