 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical laws and linguistics inform meaning in naturalistic and fictional conversation
Dec 19, 2025
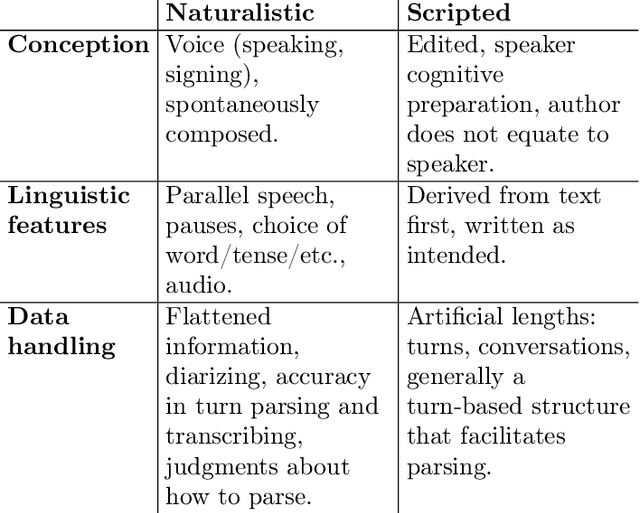
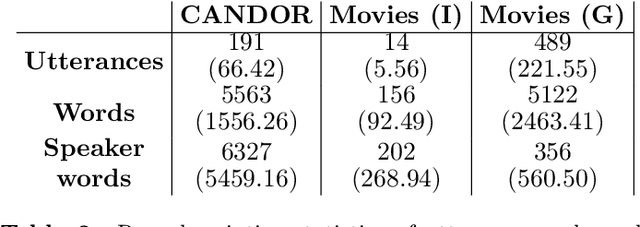
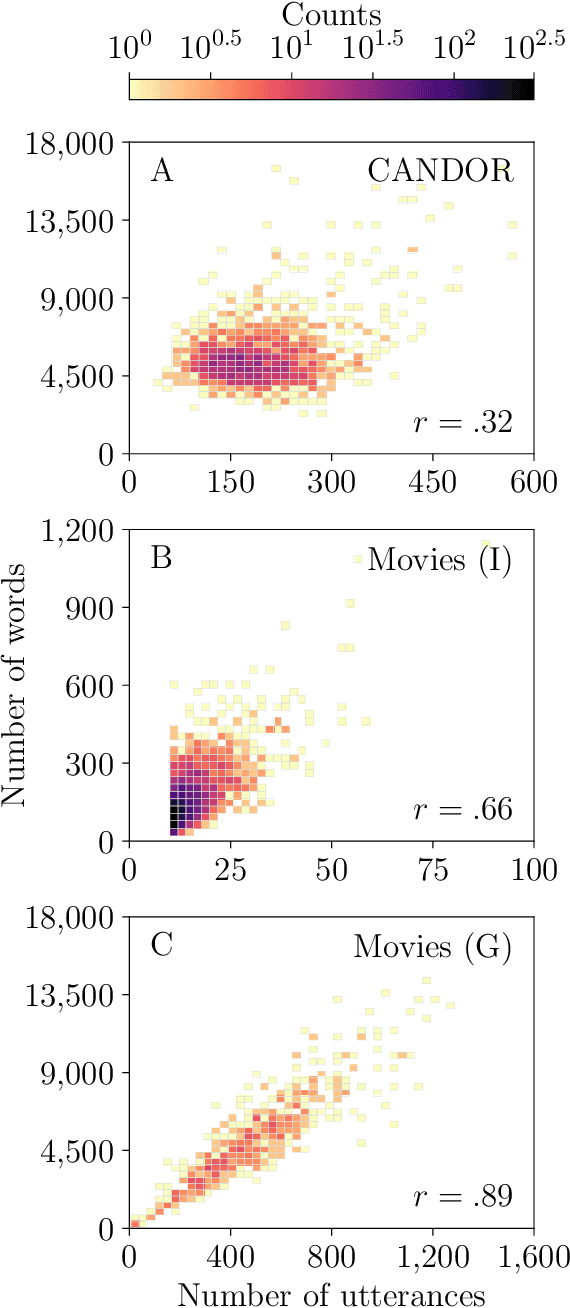
Conversation is a cornerstone of social connection and is linked to well-being outcomes. Conversations vary widely in type with some portion generating complex, dynamic stories. One approach to studying how conversations unfold in time is through statistical patterns such as Heaps' law, which holds that vocabulary size scales with document length. Little work on Heaps's law has looked at conversation and considered how language features impact scaling. We measure Heaps' law for conversations recorded in two distinct mediums: 1. Strangers brought together on video chat and 2. Fictional characters in movies. We find that scaling of vocabulary size differs by parts of speech. We discuss these findings through behavioral and linguistic frameworks.
Tokens, the oft-overlooked appetizer: Large language models, the distributional hypothesis, and meaning
Dec 14, 2024Tokenization is a necessary component within the current architecture of many language models, including the transformer-based large language models (LLMs) of Generative AI, yet its impact on the model's cognition is often overlooked. We argue that LLMs demonstrate that the Distributional Hypothesis (DM) is sufficient for reasonably human-like language performance, and that the emergence of human-meaningful linguistic units among tokens motivates linguistically-informed interventions in existing, linguistically-agnostic tokenization techniques, particularly with respect to their roles as (1) semantic primitives and as (2) vehicles for conveying salient distributional patterns from human language to the model. We explore tokenizations from a BPE tokenizer; extant model vocabularies obtained from Hugging Face and tiktoken; and the information in exemplar token vectors as they move through the layers of a RoBERTa (large) model. Besides creating sub-optimal semantic building blocks and obscuring the model's access to the necessary distributional patterns, we describe how tokenization pretraining can be a backdoor for bias and other unwanted content, which current alignment practices may not remediate. Additionally, we relay evidence that the tokenization algorithm's objective function impacts the LLM's cognition, despite being meaningfully insulated from the main system intelligence.
A blind spot for large language models: Supradiegetic linguistic information
Jun 11, 2023



Large Language Models (LLMs) like ChatGPT reflect profound changes in the field of Artificial Intelligence, achieving a linguistic fluency that is impressively, even shockingly, human-like. The extent of their current and potential capabilities is an active area of investigation by no means limited to scientific researchers. It is common for people to frame the training data for LLMs as "text" or even "language". We examine the details of this framing using ideas from several areas, including linguistics, embodied cognition, cognitive science, mathematics, and history. We propose that considering what it is like to be an LLM like ChatGPT, as Nagel might have put it, can help us gain insight into its capabilities in general, and in particular, that its exposure to linguistic training data can be productively reframed as exposure to the diegetic information encoded in language, and its deficits can be reframed as ignorance of extradiegetic information, including supradiegetic linguistic information. Supradiegetic linguistic information consists of those arbitrary aspects of the physical form of language that are not derivable from the one-dimensional relations of context -- frequency, adjacency, proximity, co-occurrence -- that LLMs like ChatGPT have access to. Roughly speaking, the diegetic portion of a word can be thought of as its function, its meaning, as the information in a theoretical vector in a word embedding, while the supradiegetic portion of the word can be thought of as its form, like the shapes of its letters or the sounds of its syllables. We use these concepts to investigate why LLMs like ChatGPT have trouble handling palindromes, the visual characteristics of symbols, translating Sumerian cuneiform, and continuing integer sequences.
An assessment of measuring local levels of homelessness through proxy social media signals
May 15, 2023Recent studies suggest social media activity can function as a proxy for measures of state-level public health, detectable through natural language processing. We present results of our efforts to apply this approach to estimate homelessness at the state level throughout the US during the period 2010-2019 and 2022 using a dataset of roughly 1 million geotagged tweets containing the substring ``homeless.'' Correlations between homelessness-related tweet counts and ranked per capita homelessness volume, but not general-population densities, suggest a relationship between the likelihood of Twitter users to personally encounter or observe homelessness in their everyday lives and their likelihood to communicate about it online. An increase to the log-odds of ``homeless'' appearing in an English-language tweet, as well as an acceleration in the increase in average tweet sentiment, suggest that tweets about homelessness are also affected by trends at the nation-scale. Additionally, changes to the lexical content of tweets over time suggest that reversals to the polarity of national or state-level trends may be detectable through an increase in political or service-sector language over the semantics of charity or direct appeals. An analysis of user account type also revealed changes to Twitter-use patterns by accounts authored by individuals versus entities that may provide an additional signal to confirm changes to homelessness density in a given jurisdiction. While a computational approach to social media analysis may provide a low-cost, real-time dataset rich with information about nationwide and localized impacts of homelessness and homelessness policy, we find that practical issues abound, limiting the potential of social media as a proxy to complement other measures of homelessness.