 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Formative Study of Brief Affective Text as a Complement to Wearable Sensing for Longitudinal Student Health Monitoring
May 14, 2026Wearable devices capture physiological and behavioral data with increasing fidelity, but the psychological context shaping these outcomes is difficult to recover from sensor data alone, limiting passive sensing utility for digital health. We examined whether ultra-brief naturalistic concern text could serve as a scalable complement to passive sensing. In a year-long study of 458 university students (3,610 person-waves) tracked with Oura rings, participants responded bimonthly to an open-ended prompt about what concerned them most; responses had a median length of three words. We compared dictionary-based, general pretrained, and domain-adapted NLP approaches using within-person mixed-effects models across nine sleep and physical activity outcomes. Weeks dominated by academic concern framing were associated with lower physical activity; weeks characterized by emotional exhaustion language were associated with poorer sleep quality and lower heart rate variability. General pretrained embeddings outperformed domain-adapted models for most outcomes, with domain adaptation showing relative advantage for autonomic outcomes. Zero-shot classification of concern topics produced no significant associations, while affective dimensions across all three methods were consistently associated with outcomes, indicating emotional register rather than topical content carries the signal. These findings offer design guidance: ultra-brief affective prompts enrich the psychological interpretability of passive physiological data at minimal burden.
Tokens, the oft-overlooked appetizer: Large language models, the distributional hypothesis, and meaning
Dec 14, 2024Tokenization is a necessary component within the current architecture of many language models, including the transformer-based large language models (LLMs) of Generative AI, yet its impact on the model's cognition is often overlooked. We argue that LLMs demonstrate that the Distributional Hypothesis (DM) is sufficient for reasonably human-like language performance, and that the emergence of human-meaningful linguistic units among tokens motivates linguistically-informed interventions in existing, linguistically-agnostic tokenization techniques, particularly with respect to their roles as (1) semantic primitives and as (2) vehicles for conveying salient distributional patterns from human language to the model. We explore tokenizations from a BPE tokenizer; extant model vocabularies obtained from Hugging Face and tiktoken; and the information in exemplar token vectors as they move through the layers of a RoBERTa (large) model. Besides creating sub-optimal semantic building blocks and obscuring the model's access to the necessary distributional patterns, we describe how tokenization pretraining can be a backdoor for bias and other unwanted content, which current alignment practices may not remediate. Additionally, we relay evidence that the tokenization algorithm's objective function impacts the LLM's cognition, despite being meaningfully insulated from the main system intelligence.
Characterizing narrative time in books through fluctuations in power and danger arcs
Aug 24, 2022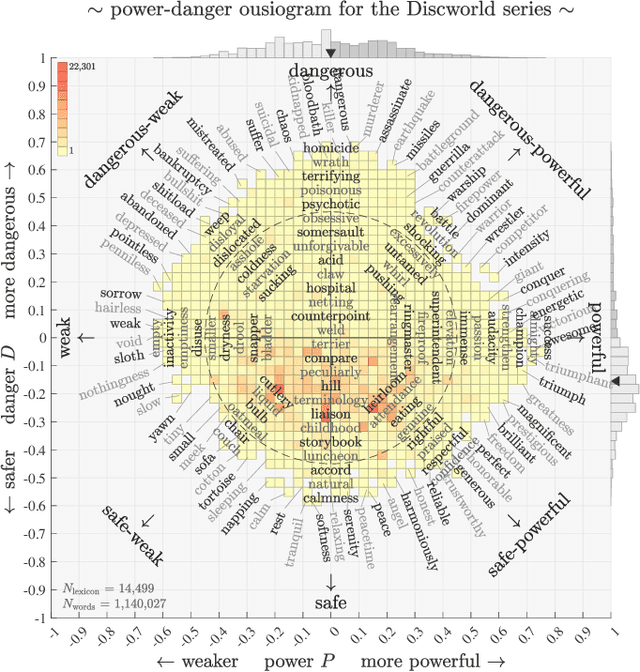
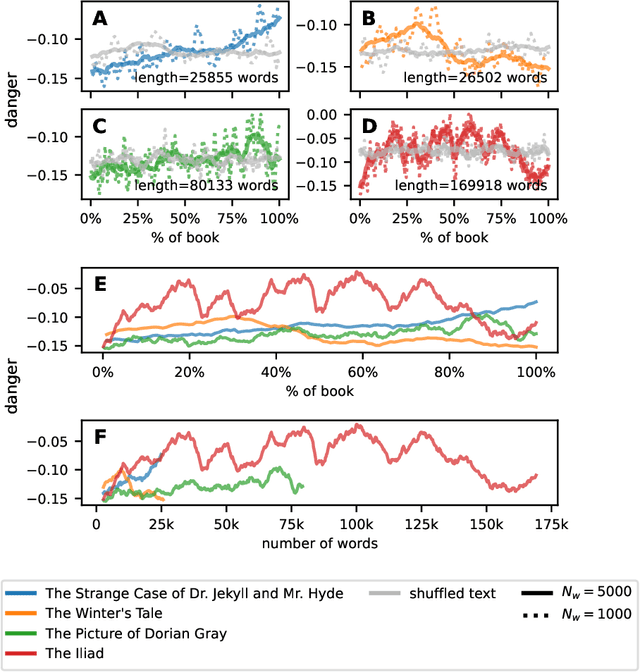
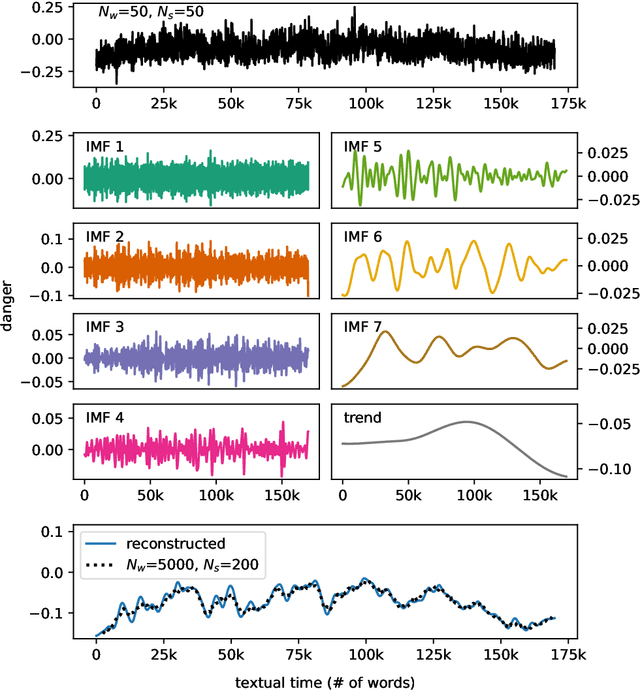
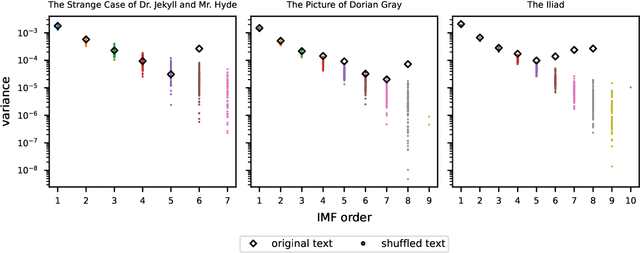
While recent studies have focused on quantifying word usage to find the overall shapes of narrative emotional arcs, certain features of narratives within narratives remain to be explored. Here, we characterize the narrative time scale of sub-narratives by finding the length of text at which fluctuations in word usage begin to be relevant. We represent more than 30,000 Project Gutenberg books as time series using ousiometrics, a power-danger framework for essential meaning, itself a reinterpretation of the valence-arousal-dominance framework derived from semantic differentials. We decompose each book's power and danger time series using empirical mode decomposition into a sum of constituent oscillatory modes and a non-oscillatory trend. By comparing the decomposition of the original power and danger time series with those derived from shuffled text, we find that shorter books exhibit only a general trend, while longer books have fluctuations in addition to the general trend, similar to how subplots have arcs within an overall narrative arc. These fluctuations typically have a period of a few thousand words regardless of the book length or library classification code, but vary depending on the content and structure of the book. Our method provides a data-driven denoising approach that works for text of various lengths, in contrast to the more traditional approach of using large window sizes that may inadvertently smooth out relevant information, especially for shorter texts.
Sentiment and structure in word co-occurrence networks on Twitter
Oct 01, 2021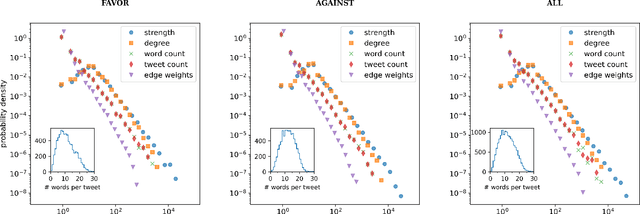
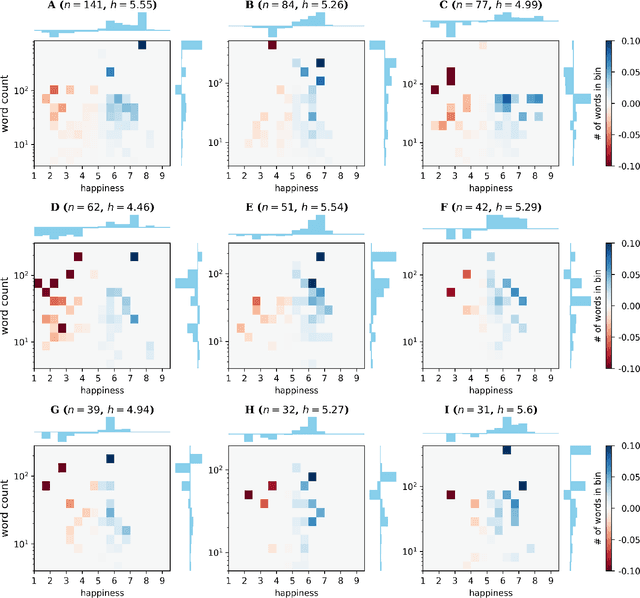
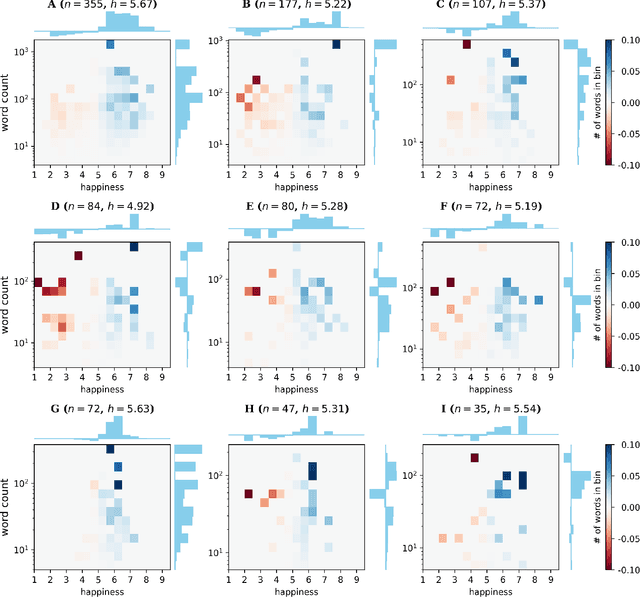
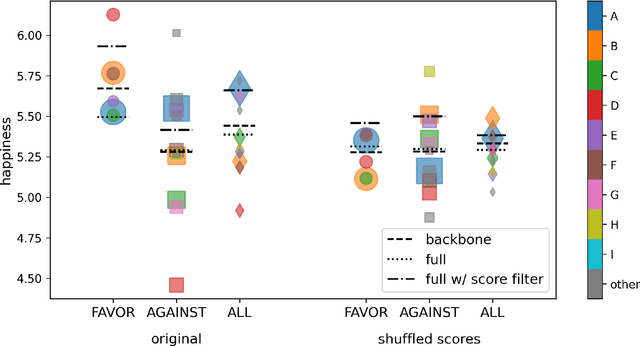
We explore the relationship between context and happiness scores in political tweets using word co-occurrence networks, where nodes in the network are the words, and the weight of an edge is the number of tweets in the corpus for which the two connected words co-occur. In particular, we consider tweets with hashtags #imwithher and #crookedhillary, both relating to Hillary Clinton's presidential bid in 2016. We then analyze the network properties in conjunction with the word scores by comparing with null models to separate the effects of the network structure and the score distribution. Neutral words are found to be dominant and most words, regardless of polarity, tend to co-occur with neutral words. We do not observe any score homophily among positive and negative words. However, when we perform network backboning, community detection results in word groupings with meaningful narratives, and the happiness scores of the words in each group correspond to its respective theme. Thus, although we observe no clear relationship between happiness scores and co-occurrence at the node or edge level, a community-centric approach can isolate themes of competing sentiments in a corpus.