 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokens, the oft-overlooked appetizer: Large language models, the distributional hypothesis, and meaning
Dec 14, 2024Tokenization is a necessary component within the current architecture of many language models, including the transformer-based large language models (LLMs) of Generative AI, yet its impact on the model's cognition is often overlooked. We argue that LLMs demonstrate that the Distributional Hypothesis (DM) is sufficient for reasonably human-like language performance, and that the emergence of human-meaningful linguistic units among tokens motivates linguistically-informed interventions in existing, linguistically-agnostic tokenization techniques, particularly with respect to their roles as (1) semantic primitives and as (2) vehicles for conveying salient distributional patterns from human language to the model. We explore tokenizations from a BPE tokenizer; extant model vocabularies obtained from Hugging Face and tiktoken; and the information in exemplar token vectors as they move through the layers of a RoBERTa (large) model. Besides creating sub-optimal semantic building blocks and obscuring the model's access to the necessary distributional patterns, we describe how tokenization pretraining can be a backdoor for bias and other unwanted content, which current alignment practices may not remediate. Additionally, we relay evidence that the tokenization algorithm's objective function impacts the LLM's cognition, despite being meaningfully insulated from the main system intelligence.
A blind spot for large language models: Supradiegetic linguistic information
Jun 11, 2023



Large Language Models (LLMs) like ChatGPT reflect profound changes in the field of Artificial Intelligence, achieving a linguistic fluency that is impressively, even shockingly, human-like. The extent of their current and potential capabilities is an active area of investigation by no means limited to scientific researchers. It is common for people to frame the training data for LLMs as "text" or even "language". We examine the details of this framing using ideas from several areas, including linguistics, embodied cognition, cognitive science, mathematics, and history. We propose that considering what it is like to be an LLM like ChatGPT, as Nagel might have put it, can help us gain insight into its capabilities in general, and in particular, that its exposure to linguistic training data can be productively reframed as exposure to the diegetic information encoded in language, and its deficits can be reframed as ignorance of extradiegetic information, including supradiegetic linguistic information. Supradiegetic linguistic information consists of those arbitrary aspects of the physical form of language that are not derivable from the one-dimensional relations of context -- frequency, adjacency, proximity, co-occurrence -- that LLMs like ChatGPT have access to. Roughly speaking, the diegetic portion of a word can be thought of as its function, its meaning, as the information in a theoretical vector in a word embedding, while the supradiegetic portion of the word can be thought of as its form, like the shapes of its letters or the sounds of its syllables. We use these concepts to investigate why LLMs like ChatGPT have trouble handling palindromes, the visual characteristics of symbols, translating Sumerian cuneiform, and continuing integer sequences.
Characterizing narrative time in books through fluctuations in power and danger arcs
Aug 24, 2022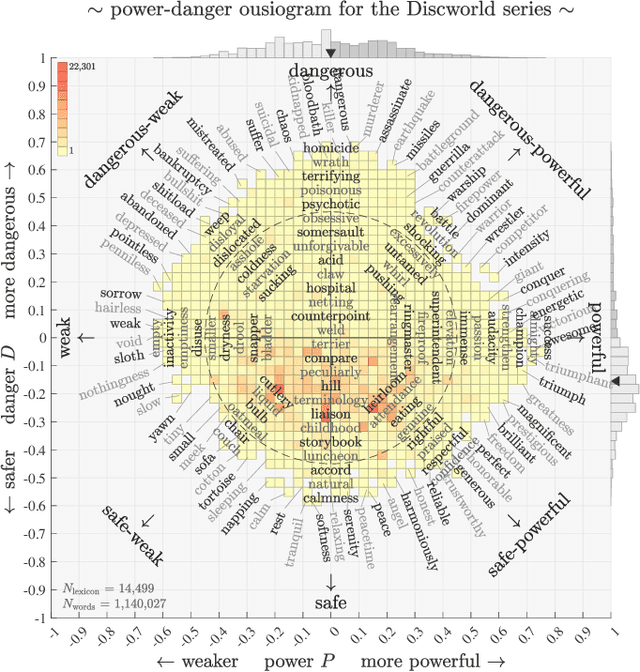
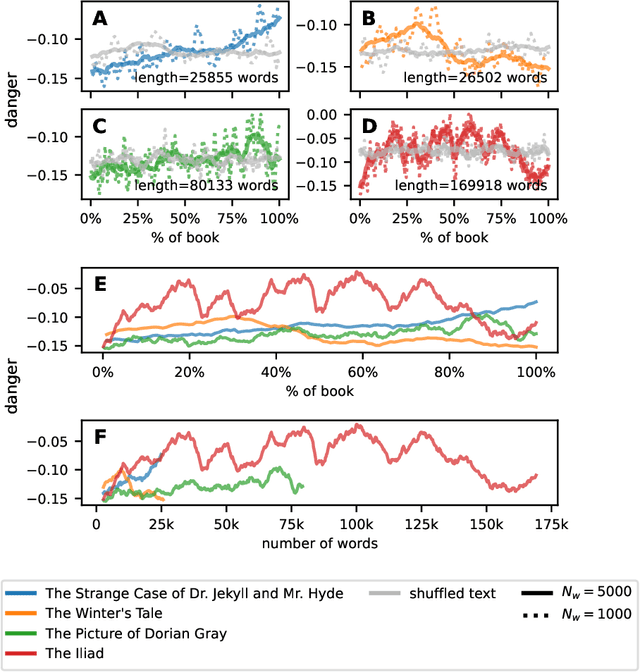
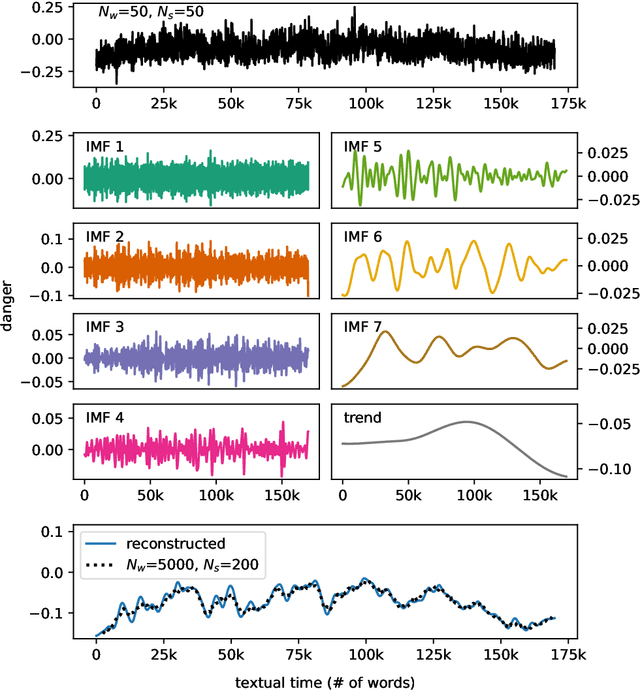
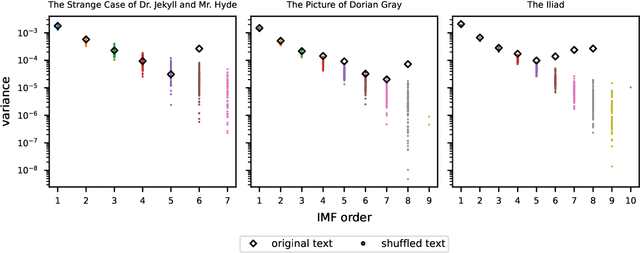
While recent studies have focused on quantifying word usage to find the overall shapes of narrative emotional arcs, certain features of narratives within narratives remain to be explored. Here, we characterize the narrative time scale of sub-narratives by finding the length of text at which fluctuations in word usage begin to be relevant. We represent more than 30,000 Project Gutenberg books as time series using ousiometrics, a power-danger framework for essential meaning, itself a reinterpretation of the valence-arousal-dominance framework derived from semantic differentials. We decompose each book's power and danger time series using empirical mode decomposition into a sum of constituent oscillatory modes and a non-oscillatory trend. By comparing the decomposition of the original power and danger time series with those derived from shuffled text, we find that shorter books exhibit only a general trend, while longer books have fluctuations in addition to the general trend, similar to how subplots have arcs within an overall narrative arc. These fluctuations typically have a period of a few thousand words regardless of the book length or library classification code, but vary depending on the content and structure of the book. Our method provides a data-driven denoising approach that works for text of various lengths, in contrast to the more traditional approach of using large window sizes that may inadvertently smooth out relevant information, especially for shorter texts.