 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable bias mitigation for textual data: Reducing gender bias in patient notes while maintaining classification performance
Mar 10, 2021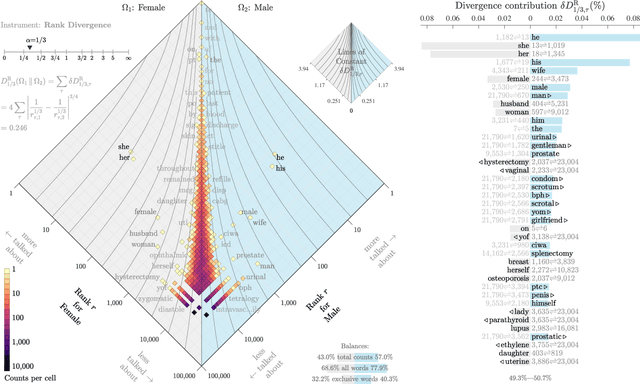
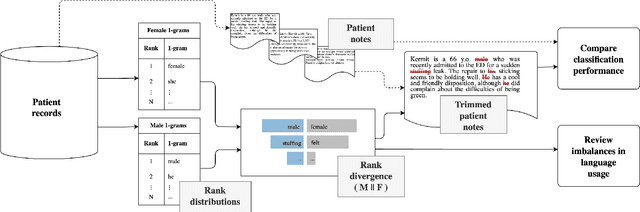
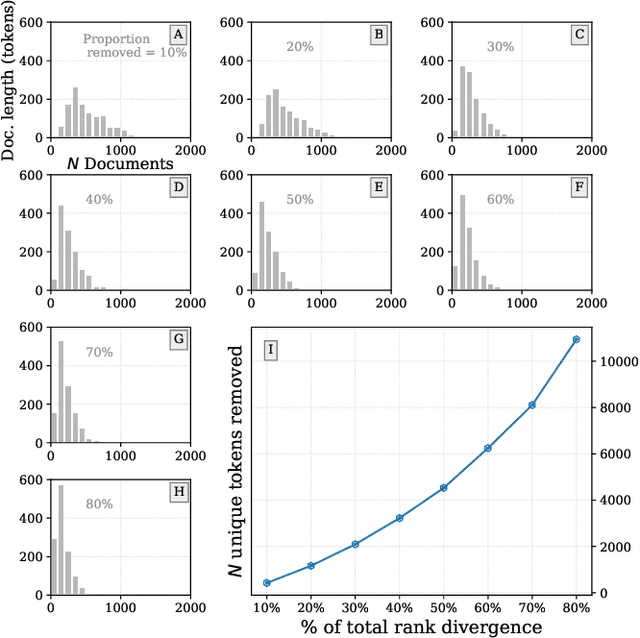
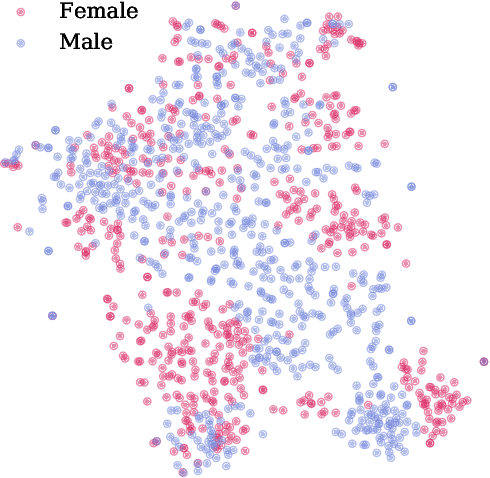
Medical systems in general, and patient treatment decisions and outcomes in particular, are affected by bias based on gender and other demographic elements. As language models are increasingly applied to medicine, there is a growing interest in building algorithmic fairness into processes impacting patient care. Much of the work addressing this question has focused on biases encoded in language models -- statistical estimates of the relationships between concepts derived from distant reading of corpora. Building on this work, we investigate how word choices made by healthcare practitioners and language models interact with regards to bias. We identify and remove gendered language from two clinical-note datasets and describe a new debiasing procedure using BERT-based gender classifiers. We show minimal degradation in health condition classification tasks for low- to medium-levels of bias removal via data augmentation. Finally, we compare the bias semantically encoded in the language models with the bias empirically observed in health records. This work outlines an interpretable approach for using data augmentation to identify and reduce the potential for bias in natural language processing pipelines.
Generating Information Extraction Patterns from Overlapping and Variable Length Annotations using Sequence Alignment
Aug 09, 2019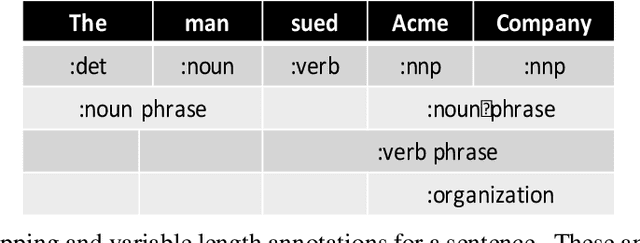

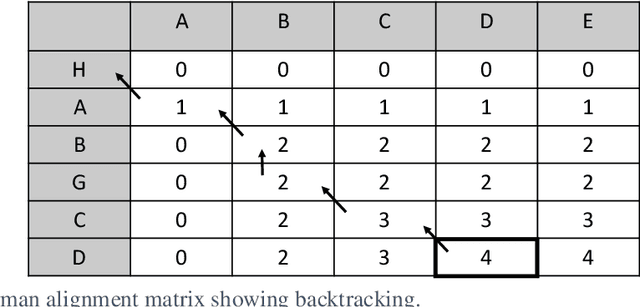
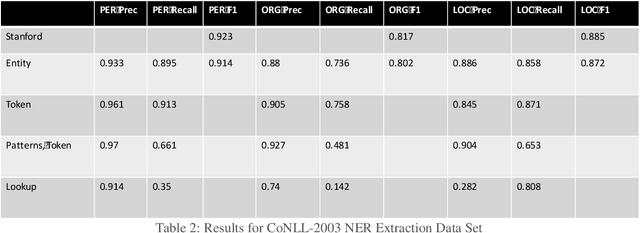
Sequence alignments are used to capture patterns composed of elements representing multiple conceptual levels through the alignment of sequences that contain overlapping and variable length annotations. The alignments also determine the proper context window of words and phrases that most directly impact the meaning of a given target within a sentence, eliminating the need to predefine a fixed context window of words surrounding the targets. We evaluated the system using the CoNLL-2003 named entity recognition (NER) task.