 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Resume Paradox: Greater Language Differences, Smaller Pay Gaps
Jul 17, 2023



Over the past decade, the gender pay gap has remained steady with women earning 84 cents for every dollar earned by men on average. Many studies explain this gap through demand-side bias in the labor market represented through employers' job postings. However, few studies analyze potential bias from the worker supply-side. Here, we analyze the language in millions of US workers' resumes to investigate how differences in workers' self-representation by gender compare to differences in earnings. Across US occupations, language differences between male and female resumes correspond to 11% of the variation in gender pay gap. This suggests that females' resumes that are semantically similar to males' resumes may have greater wage parity. However, surprisingly, occupations with greater language differences between male and female resumes have lower gender pay gaps. A doubling of the language difference between female and male resumes results in an annual wage increase of $2,797 for the average female worker. This result holds with controls for gender-biases of resume text and we find that per-word bias poorly describes the variance in wage gap. The results demonstrate that textual data and self-representation are valuable factors for improving worker representations and understanding employment inequities.
Interpretable bias mitigation for textual data: Reducing gender bias in patient notes while maintaining classification performance
Mar 10, 2021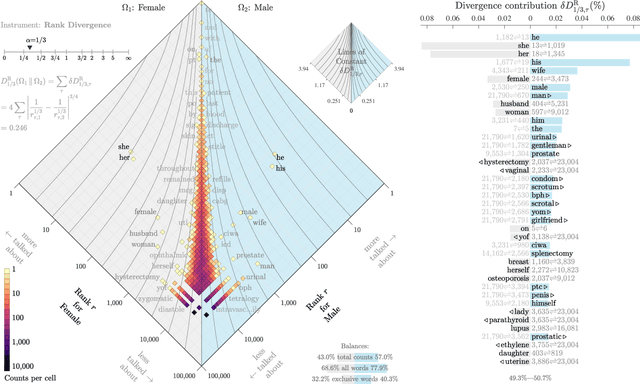
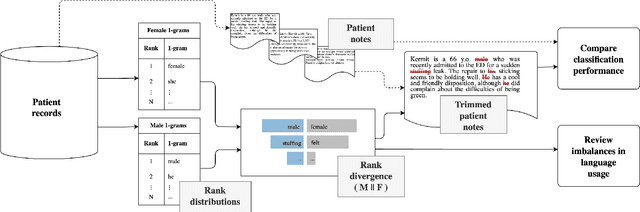
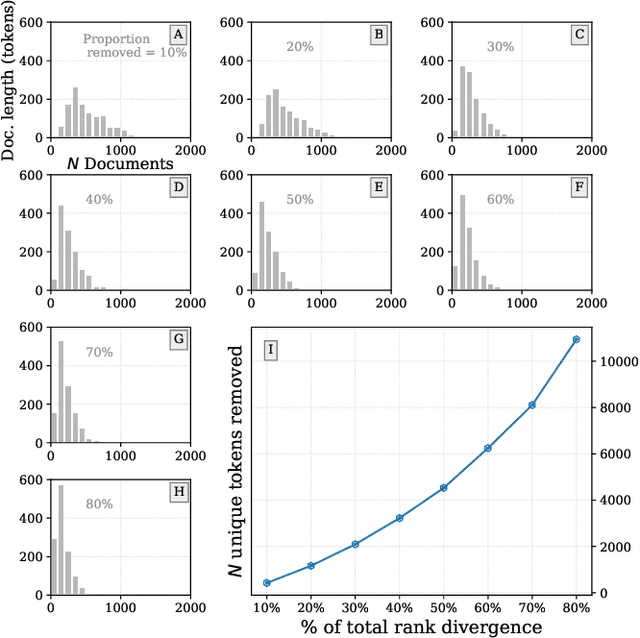
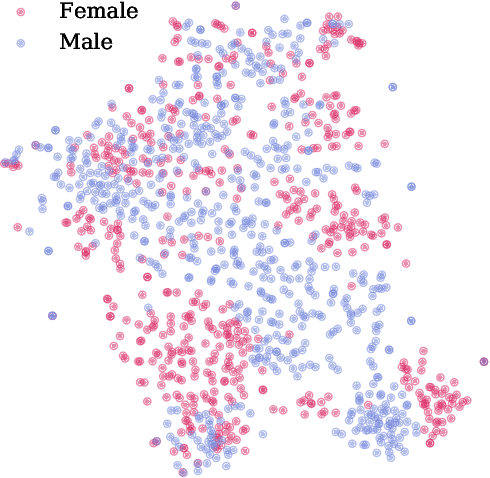
Medical systems in general, and patient treatment decisions and outcomes in particular, are affected by bias based on gender and other demographic elements. As language models are increasingly applied to medicine, there is a growing interest in building algorithmic fairness into processes impacting patient care. Much of the work addressing this question has focused on biases encoded in language models -- statistical estimates of the relationships between concepts derived from distant reading of corpora. Building on this work, we investigate how word choices made by healthcare practitioners and language models interact with regards to bias. We identify and remove gendered language from two clinical-note datasets and describe a new debiasing procedure using BERT-based gender classifiers. We show minimal degradation in health condition classification tasks for low- to medium-levels of bias removal via data augmentation. Finally, we compare the bias semantically encoded in the language models with the bias empirically observed in health records. This work outlines an interpretable approach for using data augmentation to identify and reduce the potential for bias in natural language processing pipelines.
On the Robustness of Convolutional Neural Networks to Internal Architecture and Weight Perturbations
Mar 23, 2017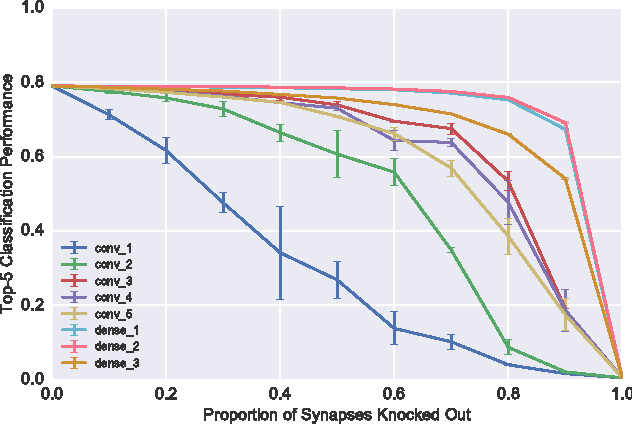
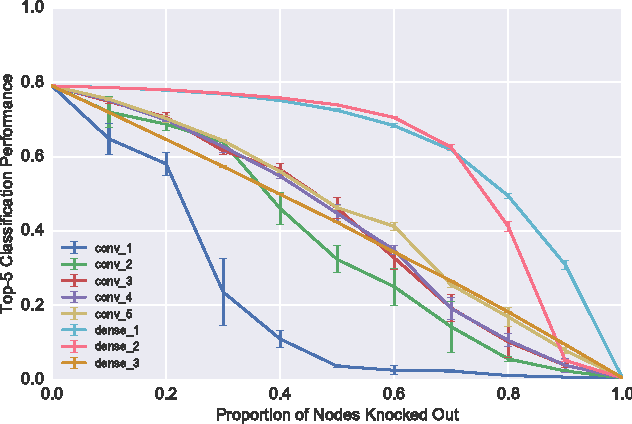
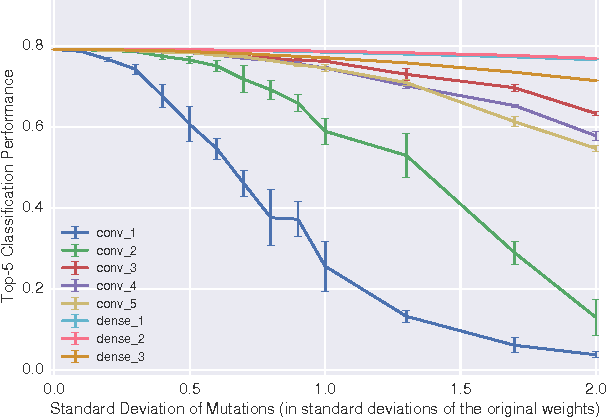
Deep convolutional neural networks are generally regarded as robust function approximators. So far, this intuition is based on perturbations to external stimuli such as the images to be classified. Here we explore the robustness of convolutional neural networks to perturbations to the internal weights and architecture of the network itself. We show that convolutional networks are surprisingly robust to a number of internal perturbations in the higher convolutional layers but the bottom convolutional layers are much more fragile. For instance, Alexnet shows less than a 30% decrease in classification performance when randomly removing over 70% of weight connections in the top convolutional or dense layers but performance is almost at chance with the same perturbation in the first convolutional layer. Finally, we suggest further investigations which could continue to inform the robustness of convolutional networks to internal perturbations.